文章目录
- 前言
- 模型框架
- 动态的NeRF
- 前处理
- 头部模型
- 音频特征
- 眼部控制
- 头部总体表示
- 躯干模型
- loss
- 结果
- 参考
【AI数字人-论文】AD-NeRF论文
前言
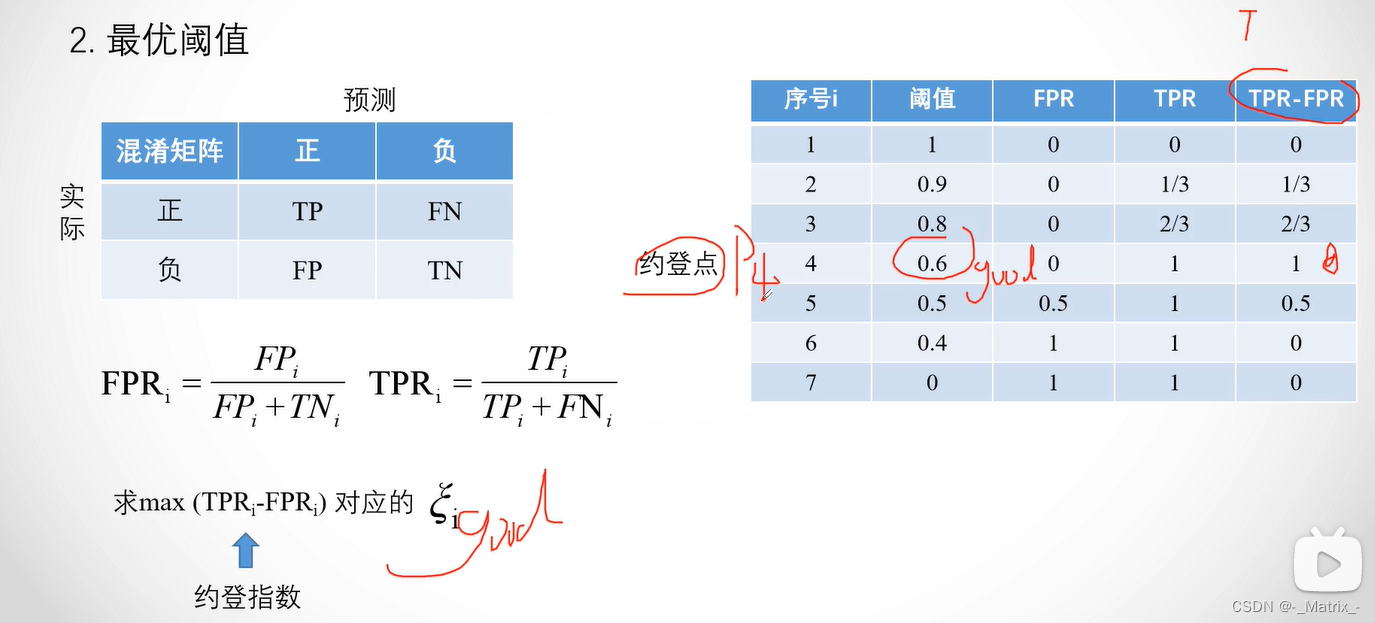
本篇论文有三个主要贡献点:
- 提出一种分解的音频空间编码模块,该模块使用两个低维特征网格有效地建模固有高维音频驱动面部动态。
- 提出一种轻量级的伪3D形变模块,更有效率地合成与头部运动同步的且自然的躯干运动
- 提出的模型框架运行更快,速度提高了500倍,同时渲染质量更高。并且还支持对说话人物的各种显式控制,如头部姿态、眨眼和更换背景图像。
模型框架

上图是RAD-NeRF的整体架构,还是沿用的AD-NeRF算法中,头和躯干分别渲染的思路。
-
头部模型是音频空间分解编码模块。输入音频信号首先通过AFE(Audio Feature Extractor)算法处理,将音频压缩到低维空间依赖音频坐标 x a x_{a} xa;然后两个分解的网格编码器(grid encoders) E s p a t i a l 3 E_{spatial}^{3} Espatial3和 E a u d i o 2 E_{audio}^{2} Eaudio2分别编码空间坐标 x x x和音频坐标 x a x_{a} xa;最后空间特征 f f f和音频特征 g g g融合到一个MLP中生成用于体渲染的头部颜色 c c c和密度 σ \sigma σ。
-
躯干模型是伪3D形变模型。每一个像素仅仅取样一个躯干坐标 x t x_{t} xt,并且在头部姿态 p p p的影响下嘘唏形变 Δ x \Delta x Δx;然后将形变坐标喂入另一个网格编码器 E t o r s o 2 E_{torso}^{2} Etorso2中得到躯干特征 f f f;最后利用一个MLP输出躯干颜色 c t c_{t} ct和alpha值 α t \alpha_{t} αt。
动态的NeRF
在动态场景的新视图合成方面,需要额外的条件(比如当前时间 t t t)。以前的方法通常通过两种方法进行动态场景建模。
-
基于形变的方法(Deformation-based methods):首先在每个位置和时间步学习一个形变 G : x , t → Δ x G:x, t \rightarrow \Delta x G:x,t→Δx,随州再将这个形变添加到原来的位置 x x x
-
基于调制的方法(Modulation-based meth):简单粗暴,将时间t作为一个条件变量约束 F F F函数: F : x , d , t → σ , c F: x, d, t \rightarrow \sigma, c F:x,d,t→σ,c
基于形变的方法由于形变区域内在的连续性,对于拓扑变换(比如嘴巴的张合)不能很好地建模,因此论文中选择用基于调制的方法建模头部区域;基于形变的方法建模躯干区域。
前处理
每个图像帧主要有三个预处理步骤:
- 对头部、颈部、躯干和背景部分进行语义解析;
- 提取2D面部坐标,包括眼睛和嘴唇;
- 进行面部跟踪以估计头部姿态参数。
对于音频处理,使用自动语音识别(ASR)模型从音频轨道中提取音频特征。
头部模型
音频特征

首先基于滑窗策略从音频流中提取音频特征,论文中是基于AFE算法,如上图所示。每个音频切片是20ms,利用一个离线的ASR算法(比如deepspeech算法)预测每个切片的分类logits l \mathbf{l} l,然后展平为1-D的卷积,经过自注意力模块得到最后的音频特征 a \mathbf{a} a。
然后降高维的音频特征 a \mathbf{a} a压缩到一个低维的音频坐标 x a ∈ R D ; D ∈ [ 1 , 2 , 3 ] x_{a} \in \mathbb{R}^{D} ; D \in [1,2,3] xa∈RD;D∈[1,2,3],通过一个MLP实现, x a = M L P ( a , f ) x_{a} = MLP(\mathbf{a}, f) xa=MLP(a,f)。在这里连接空间特征f,以使得音频坐标明确依赖于空间位置。
代替具有更高维度 g = E 3 + D ( x , x a ) g = E^{3+D\left(x,x_{a} \right)} g=E3+D(x,xa)的组合音频空间网格编码器,将其分解为两个具有较低维度的网格编码器, f = E s p a t i a l 3 ( x ) f = E_{spatial}^{3}\left( x \right) f=Espatial3(x)和 g = E a u d i o D ( x a ) g = E_{audio}^{D} \left( x_{a} \right) g=EaudioD(xa),以分别编码空间和音频坐标。
时间复杂度从 2 3 + D 2^{3+D} 23+D降到了 2 3 + 2 D 2^{3} + 2^{D} 23+2D。
眼部控制

眼球运动也是自然对话肖像合成的一个关键因素。我们提供了一种显式控制眨眼的方法。基于2D面部坐标计算整个图像中眼睛区域的百分比,并使用这个比率(通常范围在0%到0.5%之间)作为一维眼睛特征 e e e。
在NeRF网络上对这个眼睛特征进行条件约束,并表明这种简单的修改足以使模型通过普通的RGB损失学习眼睛的动态。在测试时,我们可以轻松调整眼睛百分比以控制眨眼。
头部总体表示
结合上述的分析,头部NeRF的表示可用下述公式表示:
c , σ = M L P ( f , g , e , i ) c, \sigma = MLP(f, g, e, i) c,σ=MLP(f,g,e,i)
其中 i i i是一个潜在的外观嵌入。
躯干模型
相比于头部区域,躯干区域近乎接近静态,只包括一些轻微的动作。
躯干模型是一个伪3D形变模型,实际上可以看作是一个基于形态的动态NeRF模型的2D版本,轻量级且高效率。
相比于从每条摄像射线取样一系列的点,我们仅仅从图像空间像素坐标 x t ∈ R 2 x_{t} \in \mathbb{R}^{2} xt∈R2中取样一个点即可。然后采用一个MLP预测形变 Δ x = M L P ( x t , p ) \Delta x = MLP\left( x_{t}, p \right) Δx=MLP(xt,p),头部姿态 p p p作为一个辅助变量有助于生成躯干运动和同步运动同步的形变。紧接着形变的坐标被喂入到一个2D特征网格编码器中,得到躯干特征 f t = E t o r s o 2 ( x t + Δ x ) f_{t} = E_{torso}^{2}\left( x_{t} + \Delta x \right) ft=Etorso2(xt+Δx)。最后另一个MLP被用于生成躯干颜色和alpha值 c t , α t = M L P ( f t , i t ) c_{t}, \alpha_{t} = MLP \left(f_{t}, i_{t} \right) ct,αt=MLP(ft,it),其中 i t i_{t} it是一个潜在外观嵌入,用于引入更多的模型容量。
loss


结果
将RAD-NeRF与MakeItTalk、wav2lip和AD-NeRF等算法进行了结果比较,如下图所示。RAD-NeRF在大多数指标上表示最好,并具有实时推理FPS。RAD-NeRF方法相比于基准AD-NeRF推理速度提高了约500倍,并且收敛速度也提高了约5倍。

论文中对头部建模的backbone模型的不同设置进行了实验:
- 仅使用MLP的隐式backbone(implicit backbone only using MLPs)我们采用与AD-NeRF相似的骨干网络,但使用最大占用网格剪枝进行加速。
- 具有较小MLP的组合音频空间特征网格(Composed audio-spatial feature grid with smaller MLPs)。使用普通的5D网格编码器对5D音频空间坐标进行编码。
- 具有较小MLP的分解音频空间特征网格。(Decomposed audio-spatial feature grid with smaller MLPs.)论文中测试了基于变形和调制的动态建模策略

论文中对每条射线的最大采样点数进行了实验。与一般的3D场景不同,人类头部更简单,需要更少的采样点才能达到良好的渲染质量。如下图所示,每条射线16个采样点足以合成逼真的图像,同时保持快速的推理速度。

RAD-NeRF相比于AD-NeRF算法,对视频编辑时,除了头部姿态和更换背景之外,还增加了眼部控制。

参考
- Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition