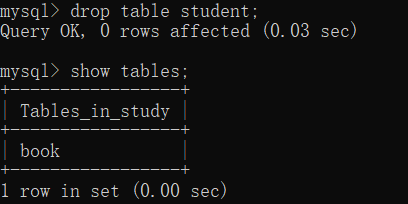
torch
张量操作(torch)
torch.tensor(): 用数据创建一个torch.Tensor对象。torch.from_numpy(): 从numpy数组创建张量。torch.zeros(),torch.ones(),torch.rand(),torch.randn(): 创建具有特定形状的全0、全1、均匀分布随机、标准正态分布随机张量。torch.arange(),torch.linspace(): 创建具有一定区间和步长的一维张量。torch.cat(),torch.stack(): 连接和堆叠多个张量。torch.save(),torch.load(): 保存和加载张量或模型状态。torch.nn.functional: 提供很多函数式的API,比如激活函数(如F.relu)、损失函数(如F.cross_entropy)等。
自动微分(torch.autograd)
torch.autograd.Variable: 弃用的类,现在所有的tensor都是Variable。torch.autograd.grad(): 计算和返回梯度。torch.autograd.backward(): 进行反向传播,自动计算所有梯度。
神经网络构建(torch.nn)
torch.nn.Module: 所有神经网络模块的基类,自定义网络应继承这个类。torch.nn.functional: 包含许多网络操作的函数版本,例如激活函数、损失函数等。- 神经网络层,如
torch.nn.Linear,torch.nn.Conv2d,torch.nn.MaxPool2d,torch.nn.Dropout等。 - 激活函数,如
torch.nn.ReLU,torch.nn.Sigmoid,torch.nn.Tanh等。 - 损失函数,如
torch.nn.MSELoss,torch.nn.CrossEntropyLoss,torch.nn.NLLLoss等。
优化器(torch.optim)
torch.optim.Optimizer: 所有优化器的基类。- 具体优化算法,如
torch.optim.SGD,torch.optim.Adam,torch.optim.RMSprop等。
数据处理(torch.utils.data)
torch.utils.data.Dataset: 表示数据集的抽象类,自定义数据集应继承这个类。torch.utils.data.DataLoader: 提供对Dataset的迭代访问,支持自动批处理、样本洗牌和多进程数据加载。
设备管理(torch.cuda)
torch.cuda.is_available(): 检查CUDA是否可用。torch.cuda.device_count(): 获取可用的GPU数量。torch.device: 表示设备的对象,可以是CPU或者GPU。
torch.nn
torch.nn 是 PyTorch 中的一个核心模块,它包含了构建神经网络所需的各种层、函数、损失函数和容器(即模型类)。以下是一些 torch.nn 模块中的关键类别和组件:
层(Layers)
nn.Linear:全连接层(线性层)。nn.Conv1d,nn.Conv2d,nn.Conv3d:一维、二维和三维的卷积层。nn.Embedding:嵌入层,用于处理例如词嵌入。nn.LSTM,nn.GRU,nn.RNN:循环神经网络层,包括LSTM和GRU等变种。nn.BatchNorm1d,nn.BatchNorm2d,nn.BatchNorm3d:批标准化层。nn.Dropout,nn.Dropout2d,nn.Dropout3d:随机丢弃层,用于正则化。nn.MaxPool1d,nn.MaxPool2d,nn.MaxPool3d:最大池化层。nn.ReLU,nn.Sigmoid,nn.Tanh,nn.ELU:激活函数层。- nn.ConvTranspose1d,nn.ConvTranspose2d,nn.ConvTranspose3d:一维、二维和三维的反卷积层。
损失函数(Loss Functions)
nn.MSELoss:均方误差损失,用于回归问题。nn.CrossEntropyLoss:交叉熵损失,用于多分类问题。nn.NLLLoss:负对数似然损失,通常与Softmax层一起使用。nn.BCELoss,nn.BCEWithLogitsLoss:二进制交叉熵损失,用于二分类问题。nn.L1Loss:L1损失,也称作平均绝对误差损失。
容器(Containers)
nn.Module:所有神经网络模块的基类。自定义的网络结构应继承自此类。nn.Sequential:一个时序容器,模块将按照它们在构造函数中被添加的顺序被添加到计算图中。
功能性(Functional)
torch.nn.functional:这是一个包含了许多函数版本的神经网络层和其他操作的模块,例如激活函数(如 F.relu),池化操作(如 F.max_pool2d)等,这些都是无状态的,因此在使用它们时需手动管理权重。
其他模块和类
nn.Parameter:一种特殊的Tensor,当它被分配为一个Module的属性时,它会自动被认为是一个模型参数。nn.utils:包含了一些实用工具,比如将多个参数张量打包为一个参数或重塑张量等。nn.init:包含各种参数初始化方法,如均匀分布、正态分布、xavier初始化等。
这只是 torch.nn 模块的一个概览,PyTorch库中还有更多的层、函数和工具可以探索。它是一个非常灵活且功能丰富的库,可以帮助研究人员和开发人员构建复杂的神经网络架构。
torch.Tensor
PyTorch 中的 Tensor 类有许多方法,这些方法允许你对张量进行数学计算、变形、索引、切片和其他类型的操作。以下是一些常用的 Tensor 类方法的概述:
创建和初始化
new_tensor(): 创建一个新的张量,复制输入数据。new_zeros(),new_ones(),new_empty(): 创建一个形状相同的新张量,但分别填充为0、1或未初始化的数据。clone(): 创建当前张量的副本。
形状和尺寸
size(): 返回张量的尺寸。view(): 重新排列张量的维度。reshape(): 改变张量的形状。permute(): 重新排列张量的维度顺序。squeeze(): 移除张量形状中为1的维度。unsqueeze(): 在指定位置增加维度为1的维度。transpose(): 交换两个维度的位置。
索引、切片、连接和分割
index_select(): 用指定索引从张量中选择数据。split(): 将张量分割成多个块。chunk(): 将张量分割成特定数量的块。cat(): 在给定维度上连接张量。stack(): 在一个新的维度上堆叠张量。
数学运算
add(),sub(),mul(),div(): 加法、减法、乘法、除法。matmul(),dot(): 矩阵乘法、点乘。exp(),log(),sqrt(): 指数、对数、平方根运算。sum(),mean(),median(),std(),var(): 总和、平均值、中位数、标准差、方差。
逻辑运算
eq(),ne(),gt(),lt(),ge(),le(): 等于、不等于、大于、小于、大于等于、小于等于。all(),any(): 判断所有或任意元素是否为True。
线性代数
norm(): 计算范数。t(): 二维张量的转置。svd(),eig(): 奇异值分解、特征值和特征向量。
内存管理
contiguous(): 确保张量在内存中是连续的。pin_memory(): 将张量固定在内存中,用于加速数据转移到CUDA设备。
硬件加速
cuda(): 将张量移动到CUDA(GPU)设备上。cpu(): 将张量移动到CPU。
操作类型和属性
dtype: 返回张量的数据类型。device: 返回张量所在的设备。requires_grad: 返回张量是否需要计算梯度。is_leaf: 判断张量是否是计算图中的叶子节点。
梯度和图
backward(): 自动微分,计算梯度。detach(): 返回一个新张量,从当前计算图中分离。
torch.nn.Parameter
在PyTorch中,nn.Parameter 是一个非常重要的类,用于表示模型中可学习的参数。nn.Parameter 继承自 torch.Tensor,它的一个主要特性是当它被分配为 nn.Module 的属性时,它会自动被注册为模型的参数,这意味着在模型训练过程中,该参数会被优化器识别并更新。
下面是一些有关 nn.Parameter 的详细信息:
自动注册
当你将一个 nn.Parameter 实例赋值给模块的某个属性时,例如 self.param = nn.Parameter(...),PyTorch 会自动将 self.param 加入到模块的参数列表中。这意味着在调用 model.parameters() 方法时,self.param 会自动被包括在内,从而允许优化器在训练过程中更新它。
与普通 Tensor 的区别
尽管 nn.Parameter 是一种特殊的 Tensor,但不同于普通的 Tensor,nn.Parameter 默认情况下是要求梯度的(requires_grad=True)。这意味着当反向传播计算梯度时,PyTorch 会自动为这些参数的梯度分配内存并进行计算。
初始化
nn.Parameter 可以通过传递一个 Tensor 来初始化。例如,如果你想创建一个可学习的权重矩阵,你可以使用 torch.randn() 来创建一个具有随机初始值的矩阵,并将其转换为 nn.Parameter。
self.weights = nn.Parameter(torch.randn(input_features, output_features))
优化器
在定义优化器时,你通常会传递模型参数的列表或生成器,如 optim.Adam(model.parameters(), lr=1e-3)。由于 nn.Parameter 被自动注册为模型参数,所以它们会被包含在 model.parameters() 返回的列表中。
下面是一个简单的自定义模块,它包含一个可学习的参数:
import torch
import torch.nn as nnclass MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()# 创建一个可学习的参数,并初始化。self.my_param = nn.Parameter(torch.tensor(1.0))def forward(self, x):# 在前向传播中使用这个参数return self.my_param * x
在这个例子中,self.my_param 将在模型训练时被优化器更新。
总之,nn.Parameter 是定义模型中可训练参数的一种简洁而强大的方式,它确保了参数可以被优化器正确管理和更新。
常用方法
torch.nn.Parameter 是一个特殊的张量类型,用于定义可学习的参数,它继承自 torch.Tensor。这意味着 torch.nn.Parameter 支持 torch.Tensor 的所有方法,而不是拥有一组独特的方法。其核心用途是将一个 Tensor 转化为模型的一个可训练参数。
参数(Parameters)是 torch.nn.Module 类的一部分,并被用来追踪所有属于模型的可训练参数。当定义一个模型的层时,通常会使用 torch.nn.Parameter 来包装权重张量,从而告诉 torch.nn.Module 这些权重需要在训练过程中被优化。
以下是使用 torch.nn.Parameter 时可以调用的一些 torch.Tensor 方法的例子:
.data: 获取参数的数据。.grad: 获取参数的梯度。.size()或.shape: 获取参数的尺寸。.to(device): 将参数移到不同的设备(例如,从CPU移到GPU)。.requires_grad_(): 启用或禁用参数的梯度计算。.zero_(): 将参数的所有元素设置为零。.uniform_(),.normal_(): 用均匀或正态分布初始化参数。
由于 torch.nn.Parameter 没有专属的子类或其他方法,其主要作用就是将 torch.Tensor 标记为模块的一个参数,并确保当调用 .parameters() 或者 .state_dict() 方法时,这个 Tensor 被包含在内并且能够被优化器更新。
创建 torch.nn.Parameter 的实例非常简单,只需要将一个 Tensor 传递给 Parameter 的构造函数。例如:
import torch
import torch.nn as nn# 创建一个Parameter实例
my_param = nn.Parameter(torch.tensor([1.0, 2.0, 3.0]))# 如果你有一个现有的Tensor,你也可以转换它
existing_tensor = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
my_param_from_existing = nn.Parameter(existing_tensor)
在自定义模块中使用 torch.nn.Parameter 时,你会将其作为模块属性,这样它就会自动地被认为是模型的一个可训练参数。这样做的一个示例如下:
class MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()self.weight = nn.Parameter(torch.randn(10, 5))self.bias = nn.Parameter(torch.zeros(5))def forward(self, x):return torch.matmul(x, self.weight) + self.bias
在上面的例子中,weight 和 bias 是通过 torch.nn.Parameter 创建的,它们会被 MyModule 的 .parameters() 方法返回,并且在调用 .backward() 后,它们的 .grad 属性将会被自动更新。
torch张量操作
PyTorch 的核心是其张量库,提供了大量的操作来创建和操作张量。以下是一些在 PyTorch 中常用的张量操作方法:
创建张量
torch.tensor(data): 根据数据创建一个张量。torch.zeros(size): 创建一个指定大小的零张量。torch.ones(size): 创建一个指定大小的全一张量。torch.arange(start, end, step): 创建一个从start到end,以step为步长的一维张量。torch.linspace(start, end, steps): 创建一个从start到end,共有steps个元素的一维张量,元素间隔均匀。torch.rand(size): 创建一个指定大小的张量,其元素从均匀分布中随机采样。torch.randn(size): 创建一个指定大小的张量,其元素从标准正态分布中随机采样。torch.eye(n): 创建一个 n×n 的单位矩阵。
修改形状和大小
.view(size): 返回一个具有新形状的张量,不改变原张量的数据。.reshape(size): 与.view()类似,但可以自动处理输入张量不连续的情况。.resize_(size): 原地修改张量的大小。.transpose(dim0, dim1): 交换两个维度的大小。.permute(*dims): 重新排列张量的维度。.squeeze(): 移除所有大小为1的维度。.unsqueeze(dim): 在指定位置插入大小为1的维度。
索引、切片和连接
torch.cat(tensors, dim): 在给定维度上连接张量序列。torch.stack(tensors, dim): 在新创建的维度上堆叠张量序列。tensor.index_select(dim, index): 在给定维度上,按照索引序列来选择数据。tensor.masked_select(mask): 根据布尔掩码选择元素。
算术和数学运算
torch.add(tensor1, tensor2): 计算两个张量的和。torch.sub(tensor1, tensor2): 计算张量的差。torch.mul(tensor1, tensor2): 计算张量的乘积。torch.div(tensor1, tensor2): 计算张量的除法。torch.mm(tensor1, tensor2): 矩阵乘法。torch.matmul(tensor1, tensor2): 张量乘法(支持广播)。torch.pow(tensor, exponent): 计算张量的幂次。
聚合操作
torch.sum(tensor, dim): 计算指定维度上的元素和。torch.mean(tensor, dim): 计算指定维度上的元素平均值。torch.max(tensor, dim): 计算指定维度上的最大值。torch.min(tensor, dim): 计算指定维度上的最小值。torch.var(tensor, dim): 计算指定维度上的方差。torch.std(tensor, dim): 计算指定维度上的标准差。
其他
tensor.clone(): 创建张量的副本。tensor.detach(): 返回一个新的张量,从当前计算图中分离,但仍指向原张量的数据。tensor.to(device): 将张量移动到不同的设备上,例如从CPU到GPU。
这只是 PyTorch 提供的张量操作方法中的一小部分。PyTorch API 非常丰富,可以进行更复杂的操作和变换。要查看所有可用的张量操作,可以查阅 PyTorch 的官方文档。
torch.nn.ModuleList
nn.ModuleList 是 PyTorch 中的一个容器模块,设计用于存储任意数量的 nn.Module 对象的列表。和 Python 的普通列表不同的是,nn.ModuleList 是一个 PyTorch 的模块,因此它会自动和所有的子模块(即其包含的 nn.Module 对象)一起被注册,并且能够确保其包含的所有模块都被正确地转换到训练或评估模式,并且所有的参数都可以被优化器识别。
主要特点
- 保持顺序:
nn.ModuleList和普通的列表一样,会保持添加模块的顺序。 - 支持常规列表操作:你可以使用常见的列表操作,如追加 (
append)、迭代 (for module in module_list)、索引访问 (module_list[i]) 等。 - 参数注册:使用
nn.ModuleList保证了其中的模块参数会被主模块正确注册,因此参数才能被 PyTorch 的优化器识别和更新。 - 模块化管理:当你的模型有很多重复的层时,使用
nn.ModuleList可以方便地管理它们,而不必单独为每一层命名。
使用场景
- 当你的神经网络中有多个相似的层或模块时,使用
nn.ModuleList来存储它们;例如,在 VGG 或 ResNet 中,有多个重复的卷积层结构。 - 当你需要构建一个具有可变数量层的网络时,比如在构建多头注意力机制时,每个头的实现可能是一个模块,头的数量根据模型的不同而变化。
示例代码
下面是一个使用 nn.ModuleList 的简单例子:
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(5)])def forward(self, x):# 依次通过所有的线性层for linear in self.linears:x = linear(x)return xmodel = MyModel()input_tensor = torch.randn(1, 10)
output_tensor = model(input_tensor)print(output_tensor)
在这个例子中,我们创建了一个包含五个相同线性层的 ModuleList。在前向传播函数 forward 中,我们可以遍历 ModuleList 并应用每个线性层。
注意事项
nn.ModuleList不是自动添加其包含的模块,你必须显式地创建nn.ModuleList并将模块添加进去。- 直接将 Python 列表转换为
nn.ModuleList不会自动注册其中的模块。你必须在创建nn.ModuleList时就填充模块,或者使用append()或extend()方法来添加模块。 nn.ModuleList仅仅是一个列表,没有定义任何前向传播(forward)方法。你需要在父模块中定义如何使用其中的模块进行前向传播。- 如果你不需要模块列表中每个模块的参数都被注册,或者你只是想要一个普通的列表,那么你可以简单地使用 Python 的内置
list。但通常,在构建 PyTorch 模型时,使用nn.ModuleList会更加安全和方便。
torch.nn.functional
torch.nn.functional 是 PyTorch 中 torch.nn 库的一个子模块,提供了一系列用于构建神经网络的函数,包括各种激活函数、损失函数、池化函数等。与 torch.nn 模块的类不同,torch.nn.functional 中的函数是无状态的,即它们不包含可训练的参数。这意味着这些函数本身不维护和学习参数,它们仅执行计算并立即返回输出。
主要特点
- 无状态:
nn.functional的函数不含状态(不含可训练参数),所以它们也不是类的实例化对象。 - 即用即走:这些函数直接对输入执行操作,并返回输出结果。
- 灵活性:由于这些函数没有参数,使用起来非常灵活。例如,你可以在训练循环中改变这些函数的行为(通过改变函数的参数),而不必重新构建网络。
包含的方法和类别
torch.nn.functional 包含了多种类型的函数,这里是一些主要的类别和示例函数:
激活函数
F.relu: 应用 rectified linear unit 激活函数。F.sigmoid: 应用 sigmoid 激活函数。F.tanh: 应用双曲正切激活函数。F.softmax: 应用 softmax 函数,通常用于分类问题的输出层。F.leaky_relu: 应用 leaky rectified linear unit 激活函数。F.prelu: 应用 parametric rectified linear unit 激活函数。
损失函数
F.mse_loss: 计算 mean squared error 损失。F.cross_entropy: 计算交叉熵损失,通常用于多分类问题。F.nll_loss: 计算负对数似然损失。F.binary_cross_entropy: 计算二进制交叉熵损失。F.binary_cross_entropy_with_logits: 结合了 sigmoid 层和二进制交叉熵损失。
卷积函数
F.conv2d: 应用二维卷积。F.conv3d: 应用三维卷积。F.conv_transpose2d: 应用二维转置卷积。
池化函数
F.max_pool2d: 应用二维最大池化。F.avg_pool2d: 应用二维平均池化。F.adaptive_max_pool2d: 应用二维自适应最大池化。F.adaptive_avg_pool2d: 应用二维自适应平均池化。
规范化函数
F.batch_norm: 应用批量归一化。F.instance_norm: 应用实例归一化。F.layer_norm: 应用层归一化。F.local_response_norm: 应用局部响应归一化。
嵌入函数
F.embedding: 根据索引从嵌入矩阵中查找嵌入向量。
其他
F.dropout: 应用 dropout 正则化。F.interpolate: 上采样或下采样给定数据。F.pad: 对输入数据进行填充。
代码示例
下面是一个使用 torch.nn.functional 中的函数的简单例子:
import torch
import torch.nn.functional as Finput_tensor = torch.randn(1, 16, 8, 8)# 使用 F.relu 应用 ReLU 激活函数
output_tensor = F.relu(input_tensor)# 使用 F.max_pool2d 应用 2x2 最大池化
output_tensor = F.max_pool2d(output_tensor, kernel_size=2)# 使用 F.cross_entropy 计算交叉熵损失
predictions = torch.randn(4, 10) # 预测值
targets = torch.randint(10, (4,)) # 真实标签
loss = F.cross_entropy(predictions, targets)print(loss)
注意事项
由于 nn.functional 的函数不包含状态,所以在使用时需要特别注意不要在这些函数中使用需要学习的参数。例如,当使用 F.conv2d 时,你需要手动定义并管理权重和偏置,而如果使用 nn.Conv2d 类,则权重和偏置会被自动管理。这使得后者在大多数情况下更加方便,特别是对于初学者。然而,nn.functional 仍然在高级使用场景和那些需要更大灵活性的地方非常有用。