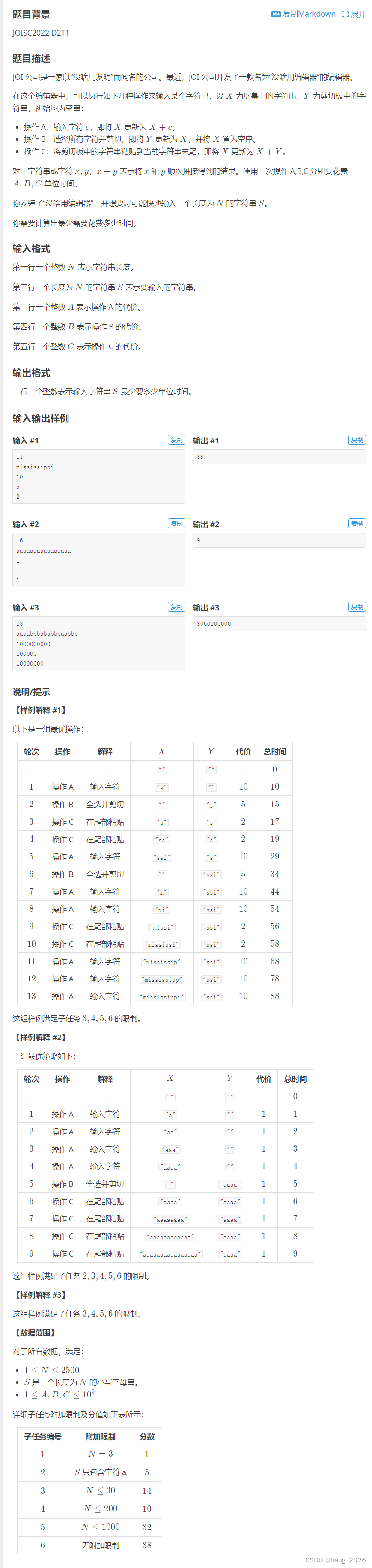
环境:windows10,centos7.9,hadoop3.2、hbase2.5.3和zookeeper3.8完全分布式;
环境搭建具体操作请参考以下文章:
CentOS7 Hadoop3.X完全分布式环境搭建
Hadoop3.x完全分布式环境搭建Zookeeper和Hbase
1. 集成MapReduce和Hbase
1)复制hbase-core.xml到$HADOOP_HOME/etc/hadop目录下
cp $HBASE_HOME/conf/hbase-core.xml $HADOOP_HOME/etc/hadoop/

注:如果是完全分布式环境,需要所有主机都要复制。包括下面的操作
2)编辑hadoop-core.xml,让HADOOP_CLASSPATH包含hbase的相关类,让mapreduce程序在运行时可以访问到这些库
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh# 在文件中写入如下内容
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/usr/local/hbase/lib/*
3)运行测试包hbase-server-2.5.3-tests.jar
cd $HBASE_HOME/lib# test 为hbase数据库中的表
hadoop jar hbase-server-2.5.3-tests.jar org.apache.hadoop.hbase/mapreduce.RowCounter test
若运行成功如下:

测试成功。
2. 批量数据导入
将需要的数据导入到Hbase中。
2.1 将数据上传到HDFS中
首先需要将数据上传到HDFS中,为将数据批量导入Hbase做准备。
1)在HDFS中新建一个文件夹/input/music2
hadoop fs -mkdir -p /input/music2
2)将数据文件(music1.txt, music2.txt, music3.txt)上传到主机上
rz # 这里使用xshell上传文件,使用rz命令,选择对应的文件即可。
3)将文件上传到HDFS的input/music2文件夹下
hadoop fs -put music1.txt music2.txt, music3.txt /input/music2 # 上传文件
hadopp fs -ls /input/music2/ # 查看文件

2.2 将数据导入到Hbase中
1)利用importtsv将准备的数据生成HFile并建表
cd $HBASE_HOME/lib # 进入hbase的lib文件夹,其中存放的是各种jar包
hadoop jar hbase-server-2.5.3.jar org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.bulk.output=tmp -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:singer,info:gender,info:ryghme,info:terminal music /input/music2 -Dcreate.table=yeshbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.bulk.output=tmp -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:singer,info:gender,info:ryghme,info:terminal music /input/music2 -Dcreate.table=yes
hbase-server-2.5.3.jar是HadoopMapReduce任务的jar包,它包含了用于将数据导入Hbase的importtsv类。
-Dimporttsv.bulk.output=tmp是一个系统属性,用于指定临时输出目录,默认是/tmp(HDFS下),使用此选项时将生成的HFile文件的内部格式问文件,这时并不会写数据到Hbase中,而是放到指定临时输出目录中即/tmp。
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:singer,info:gender,info:ryghme,info:terminal music是指定要导入到Hbase中的列。每列由列族名和列限定符组成,二者通过冒号分隔。上面的命令指定了6列,包括HBASE_ROW_KEY(每行的唯一标识符)和其他几个信息列。/input/music2 即数据在HDFS中的位置。
-Dcreate.table=yes 表示自动创建表格。
正常执行完成的结果如下:

2)将HFile数据加载到Hbase中
hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles tmp music
正常执行完成的结果如下:

3)查看hbase中的music表内容
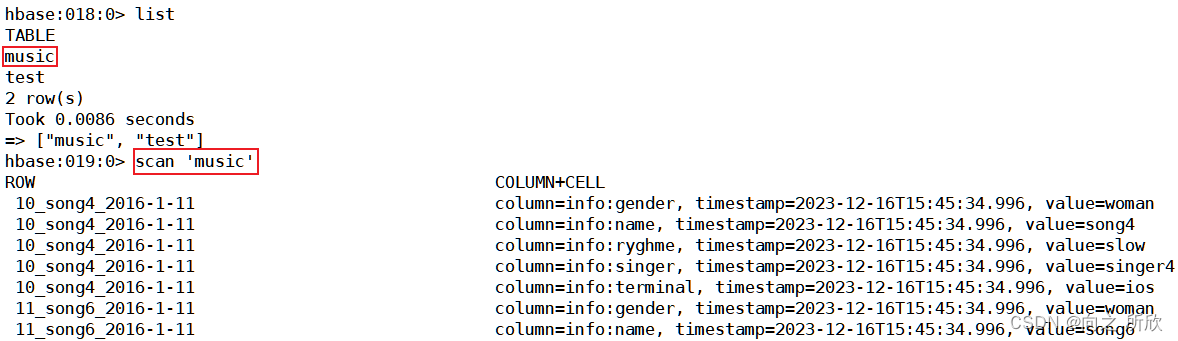
可以看到数据已经被加载到hbase的music表中。
3. 处理数据
关于HBase的存储单元cell
Hbase中的存储单元cell由一下字段组成:
1) row
2) column family
3) column qualifier
4) timestamp
5) type
6) MVCC version
7) value
3.1 项目程序源代码
3.1.1 HBaseConnect
package cn.music.TopMusic;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;import java.io.IOException;public class HBaseConnect {// 设置静态属性hbase连接public static Connection connection = null;static {try {// 使用配置文件获取服务器connection = ConnectionFactory.createConnection();} catch (IOException e) {System.out.println("连接获取失败");e.printStackTrace();}}public static void closeConnection() throws IOException {if (connection != null) {connection.close();}}
}
3.1.2 HBaseDDL
package cn.music.TopMusic;import cn.Hbaseapi.HBaseConnect;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;public class HBaseDDL {// 添加静态属性connection指向单例连接public static Connection connection = HBaseConnect.connection;/*** 判断表是否存在** @param namespace 命名空间名称* @param tableName 表名称* @return 返回判断结果* @throws IOException 异常*/public static boolean isTableExists(String namespace, String tableName) throws IOException {// 获取adminAdmin admin = connection.getAdmin();// 使用方法判断表格是否存在boolean b = false;try {b = admin.tableExists(TableName.valueOf(tableName));} catch (IOException e) {e.printStackTrace();}// 关闭adminadmin.close();return b;}/*** 创建表** @param namespace 命名空间名称* @param tableName 表名称* @param columnFamilies 列族名称*/public static void createTable(String namespace, String tableName, String... columnFamilies) throws IOException {// 判断至少有一个列族if (columnFamilies.length == 0) {System.out.println("创建表格至少有一个列族");return;}//判断表是否存在if (isTableExists(namespace, tableName)) {System.out.println("表格已经存在");return;}// 获取adminAdmin admin = connection.getAdmin();// 调用方法创建表// 创建表格描述的建造者// 只需要再建造者中各种添加参数即可,不用生成描述对象TableDescriptor或ColumnFamilyDescriptor添加参数TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tableName));//添加参数for (String columnFamily : columnFamilies) {//创建列族描述者的建造者ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));// 对应当前的列族添加参数columnFamilyDescriptorBuilder.setMaxVersions(5);// 创建添加完参数的列族描述(setColumnFamily()也可以用来在修改表操作中添加列族)tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptorBuilder.build());}// 创建对应的表格描述try {admin.createTable(tableDescriptorBuilder.build());} catch (IOException e) {// 因为之前已经判断过表是否存在了,所以再出现异常不会是表已经存在,直接输出栈追踪即可e.printStackTrace();}// 关闭adminadmin.close();}/*** 删除表** @param namespace 命名空间名称* @param tableName 表名称* @return 删除成功返回1,否则0*/public static boolean deleteTable(String namespace, String tableName) throws IOException {// 判断表格是否存在if (!isTableExists(namespace, tableName)) {System.out.println("表格不存在,无法删除");return false;}// 获取adminAdmin admin = connection.getAdmin();// 调用删除表方法try {// 删除表之前,需要先将表标记为不可用(disable)TableName tableName1 = TableName.valueOf(namespace, tableName);admin.disableTable(tableName1);admin.deleteTable(tableName1);} catch (IOException e) {e.printStackTrace();}// 关闭adminadmin.close();return true;}}
3.1.3 IntNumReducer
package cn.music.TopMusic;import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import java.io.IOException;class IntNumReducer extends TableReducer<Text, IntWritable, Text> {@Override/*** 汇总每首歌曲播放总次数** @param key // 歌名* @param values // 播放频次集合{1, 1, 1, 1}* @param context // 上下文* @throws IOException* @throws InterruptedException*/protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {// 统计每首歌的播放次数int playCount = 0;for (IntWritable num : values) {playCount += num.get();}// 为Put操作指定行键Put put = new Put(Bytes.toBytes(key.toString()));// 为Put操作指定列和值put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"),Bytes.toBytes(playCount));context.write(key, put);}}
3.1.4 IntWritableDecreaseingComparator
package cn.music.TopMusic;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;/*** 实现降序排序类*/
class IntWritableDecreaseingComparator extendsIntWritable.Comparator {@Overridepublic int compare(WritableComparable a, WritableComparable b) {return -super.compare(a, b);// 比较结果取负数即可降序}@Overridepublic int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {return -super.compare(b1, s1, l1, b2, s2, l2);}
}3.1.5 ScanMusicMapper
package cn.music.TopMusic;import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import java.io.IOException;
import java.util.List;/*** 扫描每一行数据中的列info:name*/
class ScanMusicMapper extends TableMapper<Text, IntWritable> {@Override/*** 扫描文件内容,输出键值对<"歌名": 1>* @param key // 行键* @param value // 一个数据* @param context // 上下文* @throws IOException* @throws InterruptedException*/protected void map(ImmutableBytesWritable key, Result value,Context context) throws IOException, InterruptedException {List<Cell> cells = value.listCells();for (Cell cell : cells) {if (Bytes.toString(CellUtil.cloneFamily(cell)).equals("info") &&Bytes.toString(CellUtil.cloneQualifier(cell)).equals("name")) {context.write(new Text(Bytes.toString(CellUtil.cloneValue(cell))), // 歌名new IntWritable(1));}}}
}3.1.6 ScanMusicNameMapper
package cn.music.TopMusic;import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;import java.io.IOException;
import java.util.List;/*** 处理经过一次mapreduce后的数据* 扫描全部歌曲名称并获得每首歌曲被播放次数* 输出键/值:播放次数/歌名* 输出目的地:HDSF文件*/
class ScanMusicNameMapper extends TableMapper<IntWritable, Text> {@Overrideprotected void map(ImmutableBytesWritable key, Result value,Context context) throws IOException, InterruptedException {List<Cell> cells = value.listCells();for (Cell cell : cells) {context.write(new IntWritable(Bytes.toInt(CellUtil.cloneValue(cell))), // 播放次数new Text(Bytes.toString(key.get()))); // 歌名}}
}3.1.7 TopMusic.java
package cn.music.TopMusic;import java.io.IOException;
import java.io.InputStream;import cn.Hbaseapi.HBaseConnect;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class TopMusic {static final String TABLE_MUSIC = "music";static final String TABLE_NAMELIST = "namelist";static final String OUTPUT_PATH = "hdfs://hadoop00:9000/output/topmusic";// 设置Hbase的静态配置static Configuration conf = HBaseConfiguration.create();/*** 配置job作业:第一次mapreduce、统计每首歌曲播放的总次数* @param args 命令行参数* @return Job任务是否运行成功 0 1* @throws IOException IO异常* @throws ClassNotFoundException 未找到类异常* @throws InterruptedException 阻塞方法收到中断请求的时候抛出的异常*/public static boolean musicCount(String[] args)throws IOException, ClassNotFoundException, InterruptedException {// 设置Job实例Job job = Job.getInstance(conf);// MapReduce程序作业基本配置job.setJarByClass(TopMusic.class);// 设置两个ReduceTaskjob.setNumReduceTasks(2);// 设置扫描的列族:列名 即 info:nameScan scan = new Scan();scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));// 使用hbase提供的工具类来设置job// 设置输入表名、扫描对象、Mapper的类型、输出的键值对类型、Job对象TableMapReduceUtil.initTableMapperJob(TABLE_MUSIC, scan,ScanMusicMapper.class, Text.class, IntWritable.class, job);// 判断输出表是否存在,如果不存在,则创建表,如果存在,删除重名表后重新创建。if (!HBaseDDL.isTableExists("default", TABLE_NAMELIST)) {HBaseDDL.createTable("default", TABLE_NAMELIST, "details");} else {if (HBaseDDL.deleteTable("default", "namelist")) {System.out.println("表删除成功");HBaseDDL.createTable("default", "namelist", "details");} else {System.exit(0);}}// 设置输出表名、Reducer的类型、Job对象TableMapReduceUtil.initTableReducerJob(TABLE_NAMELIST,IntNumReducer.class, job);return job.waitForCompletion(true);}/*** 配置job作业:第二次次mapreduce(只重写了map函数),自定义比较器,利用shuffle对数据进行降序排序* @param args 命令行参数* @return job实例是否成功运行 0 1* @throws IOException IO异常* @throws ClassNotFoundException 未找到类异常* @throws InterruptedException 阻塞方法收到中断请求的时候抛出此异常*/public static boolean sortMusic(String[] args)throws IOException, ClassNotFoundException, InterruptedException {// 设置Job实例Job job = Job.getInstance(conf, "sort-music");job.setJarByClass(TopMusic.class);job.setNumReduceTasks(1);// 设置比较器类job.setSortComparatorClass(IntWritableDecreaseingComparator.class);// 设置输出表、扫描对象、Mapper类、键值对类型、job实例TableMapReduceUtil.initTableMapperJob(TABLE_NAMELIST, new Scan(),ScanMusicNameMapper.class, IntWritable.class, Text.class, job);// 将排序后的数据文件输出到指定路径下Path output = new Path(OUTPUT_PATH);if (FileSystem.get(conf).exists(output))FileSystem.get(conf).delete(output, true);FileOutputFormat.setOutputPath(job, output);return job.waitForCompletion(true);}/*** 查看输出文件,获取最终的排名数据* @throws IllegalArgumentException 非法参数异常* @throws IOException IO异常*/public static void showResult() throws IllegalArgumentException, IOException{// 获取文件系统对象FileSystem fs = FileSystem.get(conf);// 输出路径下的文件内容InputStream in = null;try {in = fs.open(new Path(OUTPUT_PATH+"/part-r-00000"));IOUtils.copyBytes(in, System.out, 4096, false);} finally {IOUtils.closeStream(in);}}// 主函数public static void main(String[] args) throws IOException,ClassNotFoundException, InterruptedException {// 关于GenericOptionsParser:是hadoop框架中解析命令行参数的基本类。// 它能够辨别一些标准的命令行参数,能够使应用程序轻易地指定namenode,jobtracker,// 以及其他额外的配置资源。GenericOptionsParser gop = new GenericOptionsParser(conf, args);String[] otherArgs = gop.getRemainingArgs(); // 获取命令行参数// 如果musicCount()成功执行,那么执行sortMusic(),如果sortMusic执行成功,调用showResult()展示处理结果if (musicCount(otherArgs)) {if (sortMusic(otherArgs)) {showResult();}}}
}
3.2 运行结果
控制台输出结果如下:

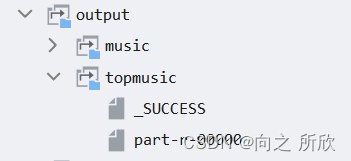
输出结果存储到HDFS如下:
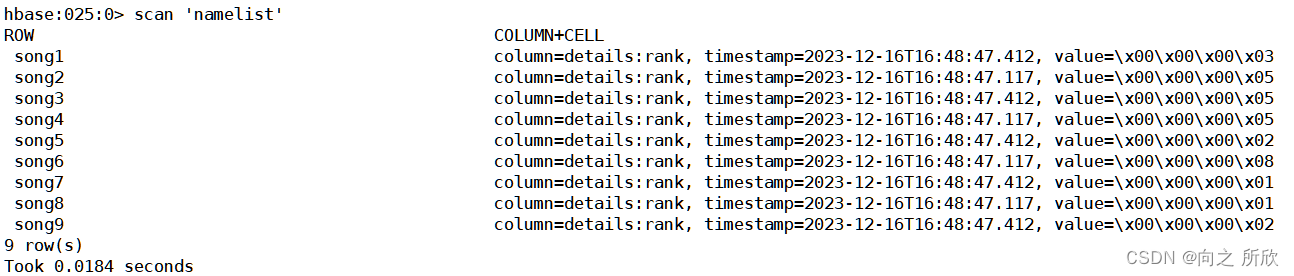
Hbase中namelist表内容如下:
 至此,大数据开发项目–音乐排行榜项目完成。
至此,大数据开发项目–音乐排行榜项目完成。