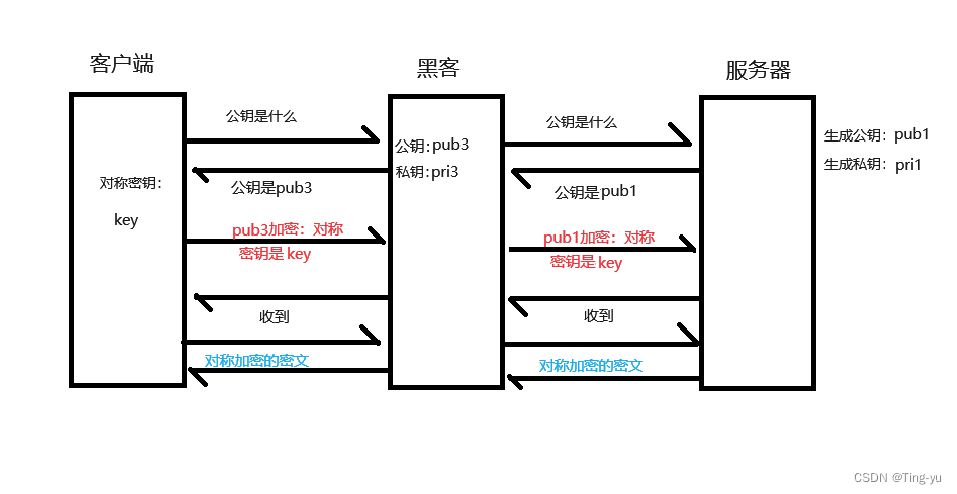
今天这篇推文,我们继续空间数据可视化的最后一个系列-类别插值(categorical-spatial-interpolation) 可视化绘制的推文教程,这期我们使用Python进行绘制,涉及的知识点如下:
-
sklearn.KNeighborsClassifier()机器学习应用
-
plotnine 多数值映射绘图设置
-
所有完整代码都已整理之我们的线上课程,有需要的同学+v yidianshuyulove 咨询
(两大知识点,其中还会涉及几个小点知识,会明确指出)
sklearn.KNeighborsClassifier()
终于这篇推文将机器学习和可视化完美的结合起来,即:机器学习处理数据,数据可视化技术展现、美化数据(以后的深度学习部分也会延续这个风格,只不过比重不同而已)。首先,我们给出我们今天的数据:散点数据和四川省的地图文件,python读取操作如下:
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifierdata = pd.read_excel(r"sichuan_df_label.xlsx")
import geopandas as gpd
si_map = gpd.read_file(r"四川省.json")
预览如下: 散点:

地图文件:

计算网格插值
这一步之前的推文中已说了很多次,这次我们设置800x800的网格,边界设置依据还是我们地图文件的经纬度范围,代码如下:
bounds = si_map.total_bounds
grid_size = 800
grid_lon = np.linspace(bounds[0],bounds[2],grid_size)
grid_lat = np.linspace(bounds[1],bounds[3],grid_size)
xgrid, ygrid = np.meshgrid(grid_lon, grid_lat)
#将插值网格数据整理
df_grid =pd.DataFrame(dict(lon=xgrid.flatten(),lat=ygrid.flatten()))
df_grid.head()
结果如下:

接下来,我们就是使用机器学习技术在基于点数据属性的基础上构建分类模型,再将训练好的模型应用到我们插值生成的数据上(尽量大白话,让你们更加好理解)
构建knn类模型
这一部分,我们将使用机器学习中最常用的sklearn包进行分类模型的构建及在新数据(网格插值数据)上的应用。详细代码如下:
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=100,weights="distance")
neigh_al = neigh.fit(X.values,y.values)
这样我们就构建了一个机器学习的分类模型了,其中KNeighborsClassifier的其他属性,大家可以去 sklearn 官网 进行查看哈。接下来,我们将使用构建好的neigh_al模型应用在我们的插值数据上,代码如下:
x_test = df_grid[["lon",'lat']].values
knn_result = neigh_al.predict(x_test)
knn_result
##
#array([2, 2, 2, ..., 1, 1, 1], dtype=int64)
可以看到,我们已经对每一组数据生成相应的分类结果了,由于我们作图还需使用到分类可能性数据,我们使用predict_proba方法计算其分类结果在不同类别上的可能性(最终的分类结果是取可能性最大的对应结果的)。
knn_result_pro = neigh_al.predict_proba(x_test)
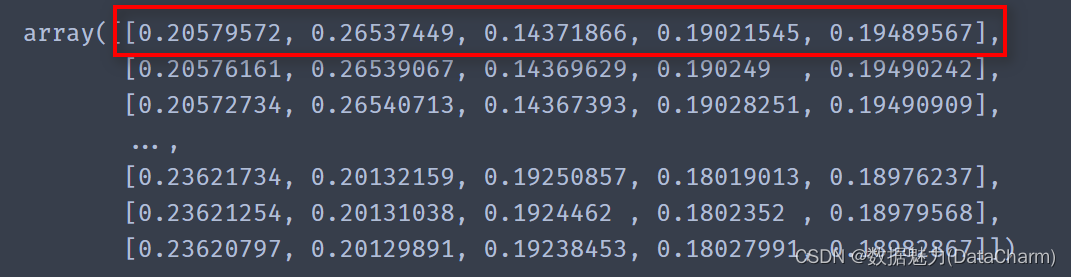
我们需要将结果保存,则需要对knn_result_pro结果进行操作,即筛选出每一个结果的最大值,这里使用np.amax() 方法操作,代码如下:
knn_result_pro_max = np.amax(knn_result_pro,axis=1)
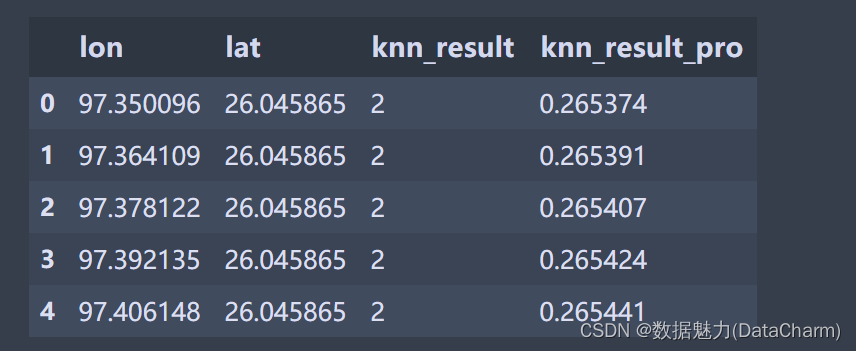
结果另存:
df_grid["knn_result"] = knn_result
df_grid["knn_result_pro"] = knn_result_pro_max
df_grid.head()
plotnine 可视化绘制
使用分类模型将结果计算出,并规整完毕,接下来就可以进行可视化绘制了,这里我们使用Plotnine 包进行绘制,代码如下:
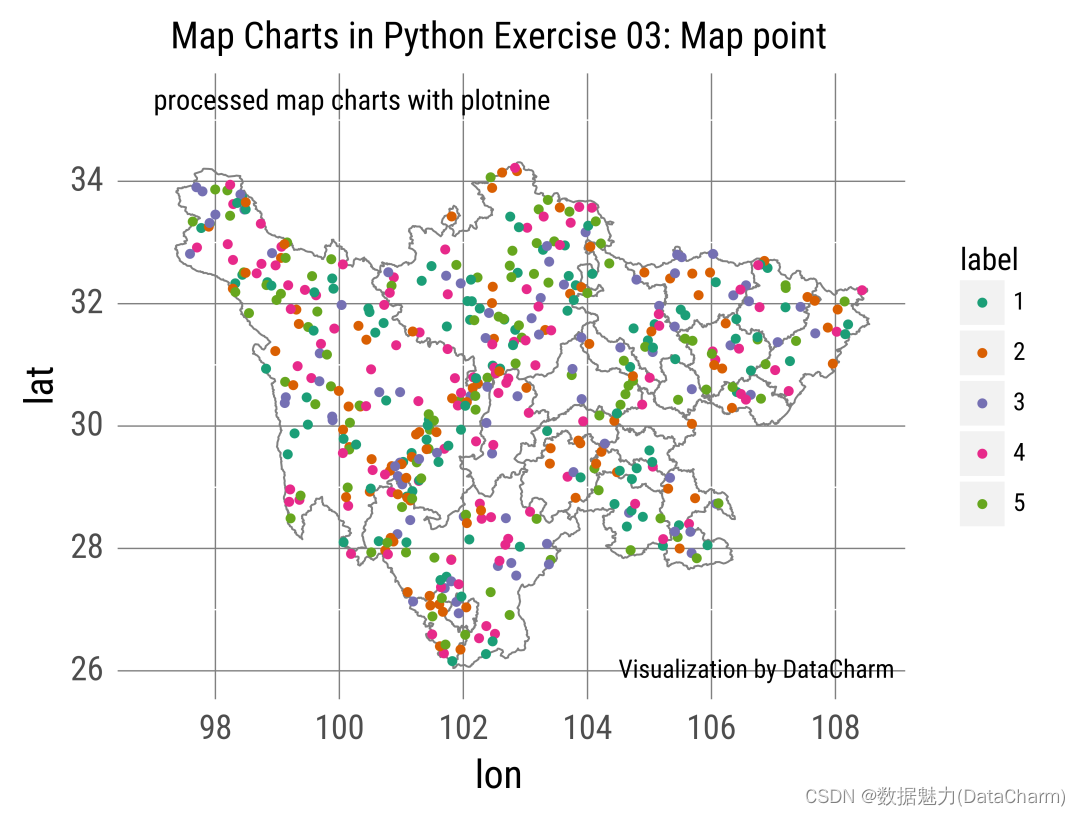
「散点分布图:」
import plotnine
from plotnine import *
plotnine.options.figure_size = (5, 4.5)
point_map = (ggplot() + geom_map(sichuan,fill='none',color='gray',size=0.4) +geom_point(data,aes(x='lon',y='lat',color='label'),size=1) +scale_color_cmap_d(name = "Dark2")+xlim(97,109)+ylim(25.8,34.5)+scale_x_continuous(breaks=[98,100,102,104,106,108])+scale_y_continuous(breaks=[26,28,30,32,34,36,38])+labs(title="Map Charts in Python Exercise 03: Map point",)+#添加文本信息annotate('text',x=97,y=35.3,label="processed map charts with plotnine",ha="left",size=10)+annotate('text',x=104.5,y=26,label="Visualization by DataCharm",ha="left",size=9)+theme(text=element_text(family="Roboto Condensed"),#修改背景panel_background=element_blank(),axis_ticks_major_x=element_blank(),axis_ticks_major_y=element_blank(),axis_text=element_text(size=12),axis_title = element_text(size=14),panel_grid_major_x=element_line(color="gray",size=.5),panel_grid_major_y=element_line(color="gray",size=.5),))
可视化结果如下:
「插值网格可视化:」
import plotnine
from plotnine import *
plotnine.options.figure_size = (5, 4.5)#mycolor = ["#1B9E77","#D95F02","#7570B3","#E7298A","#66A61E"]
knn_map_grid = (ggplot(data=knn_grid) + geom_map(sichuan,fill='none',color='gray',size=0.4) +aes(fill="knn_result")+geom_tile(knn_grid,aes(x="lon",y="lat",color='knn_result',alpha="knn_result_pro"),size=.1,show_legend={'alpha': False}) +scale_color_cmap_d(name = "Dark2")+xlim(97,109)+ylim(25.8,34.5)+scale_x_continuous(breaks=[98,100,102,104,106,108])+scale_y_continuous(breaks=[26,28,30,32,34,36,38])+labs(title="Map Charts in Python Exercise 03: Categorical Interpolation Grid",)+#添加文本信息annotate('text',x=97,y=35.3,label="processed map charts with plotnine",ha="left",size=10)+annotate('text',x=104.5,y=26,label="Visualization by DataCharm",ha="left",size=9)+theme(text=element_text(family="Roboto Condensed"),#修改背景panel_background=element_blank(),axis_ticks_major_x=element_blank(),axis_ticks_major_y=element_blank(),axis_text=element_text(size=12),axis_title = element_text(size=14),panel_grid_major_x=element_line(color="gray",size=.5),panel_grid_major_y=element_line(color="gray",size=.5),))
knn_map_grid
可视化结果如下:
这里由于将类别(label)和可能性(pro)分别映射在color(颜色和)alpha(透明度),注意如下代码(与ggplot2绘制有所不同):
(ggplot(data=knn_grid) + geom_map(sichuan,fill='none',color='gray',size=0.4) +aes(fill="knn_result")+geom_tile(knn_grid,aes(x="lon",y="lat",color='knn_result',alpha="knn_result_pro"),size=.1,show_legend={'alpha': False}) +
若是采用类似ggplot2的映射理念绘图,即采用如下代码绘制:
ggplot() + geom_map(sichuan,fill='none',color='gray',size=0.4) +geom_tile(knn_grid,aes(x="lon",y="lat",color='knn_result',alpha="knn_result_pro"),size=.1,show_legend={'alpha': False})
得到的可视化结果如下:

图中红框部分怎不能很好的表达图表含义。
裁剪操作
这一步也是说了很多次了,将模型预测结果转换geopandas 数据 类型,再使用clip() 方法裁剪即可,我们直接给出绘图代码:
#绘图
import plotnine
from plotnine import *
plotnine.options.figure_size = (5, 4.5)#mycolor = ["#1B9E77","#D95F02","#7570B3","#E7298A","#66A61E"]
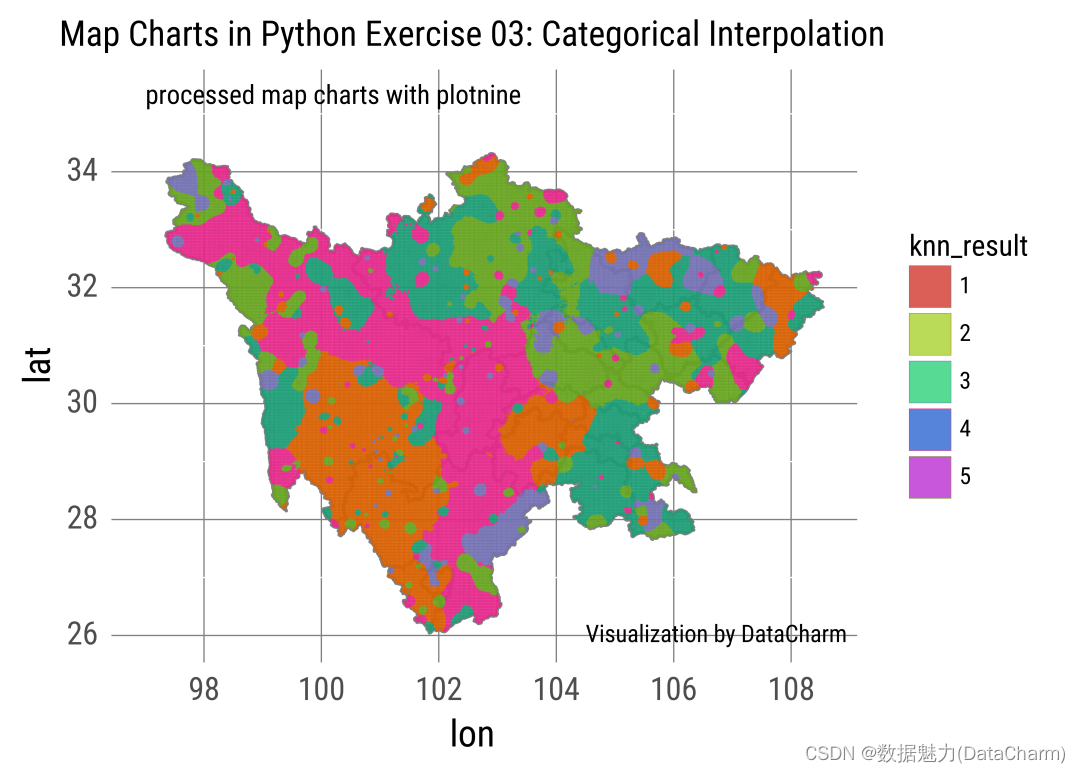
knn_map_grid_clip = (ggplot(data=knn_grid_clip) + geom_map(sichuan,fill='none',color='gray',size=0.7) +aes(fill="knn_result")+geom_tile(knn_grid_clip,aes(x="lon",y="lat",color='knn_result',alpha="knn_result_pro"),size=.1,show_legend={'alpha': False}) +scale_color_cmap_d(name = "Dark2")+xlim(97,109)+ylim(25.8,34.5)+scale_x_continuous(breaks=[98,100,102,104,106,108])+scale_y_continuous(breaks=[26,28,30,32,34,36,38])+labs(title="Map Charts in Python Exercise 03: Categorical Interpolation",)+#添加文本信息annotate('text',x=97,y=35.3,label="processed map charts with plotnine",ha="left",size=10)+annotate('text',x=104.5,y=26,label="Visualization by DataCharm",ha="left",size=9)+theme(text=element_text(family="Roboto Condensed"),#修改背景panel_background=element_blank(),axis_ticks_major_x=element_blank(),axis_ticks_major_y=element_blank(),axis_text=element_text(size=12),axis_title = element_text(size=14),panel_grid_major_x=element_line(color="gray",size=.5),panel_grid_major_y=element_line(color="gray",size=.5),))
最终我们的可视化结果如下:
注意:
由于以上数据的*类别列(label)*是直接随机生成的,可能是连续性数值,所以在绘图之前,需要添加如下类型转换操作代码:
knn_grid["knn_result"] = knn_grid["knn_result"].astype("object")
总结
这一期的可视化绘制推文,我们加入了机器学习的内容(也算是机器学习相关的第一篇推文),原理性的东西我这边尽量少介绍,我们关注的是实际应用,无论是可视化的数据处理、各个领域的应用等,希望这篇推文对大家的可视化设计或者机器学习等知识面都有所帮助。