一、引言
在当今快速变化的证券市场中,信息的价值不言而喻。作为一名资深项目经理,我曾领导一个关键项目,旨在通过先进的信息抽取技术,从海量的文本数据中提取关键事件,如企业并购、新产品发布以及政策环境的变动。这些事件对于投资决策至关重要,因为它们直接影响市场动态和投资者的策略。我们的项目通过自然语言处理(NLP)和机器学习算法,能够自动识别和分类这些事件,为投资策略提供实时、准确的数据支持。这不仅提高了决策效率,也为投资者在复杂多变的市场环境中寻找到了新的竞争优势。
二、用户案例
在项目初期,我们面临的挑战是如何从大量的新闻报道、财报和社交媒体中快速准确地识别出对证券市场有重大影响的事件。例如,我们需要实时监控并分析一家公司宣布的季度盈利报告,以判断其对股价的潜在影响。传统的手动筛选方法耗时且效率低下,而且容易遗漏关键信息。

为了解决这个问题,我们引入了信息抽取技术。通过参数抽取,我们能够自动从文本中提取出关键的财务指标,如收入、利润率和市场份额等。这些数值信息与公司的实体自动关联,形成了一个动态更新的数据集,为分析师提供了一个强大的决策支持工具。
在项目进行中,我们进一步利用了实体抽取和属性抽取技术。这使我们能够识别出文本中提到的所有相关实体,如公司、产品、竞争对手,以及它们的描述性特征。例如,我们能够快速识别出一家科技公司发布的新产品,并自动提取出产品的关键属性,如发布日期、价格和预期销量。这些信息对于投资者评估市场趋势和制定投资策略至关重要。
随着项目的深入,关系抽取和事件抽取技术发挥了关键作用。我们不仅能够识别出实体之间的关联,如合作伙伴关系或竞争对手,还能够理解这些关系背后的复杂语境。例如,当一家制药公司宣布获得新药批准时,我们能够自动抽取出与此事件相关的所有实体,如药物名称、研发阶段、预期市场等,并构建出事件的完整图景。这对于预测市场反应和投资机会至关重要。
通过这些技术的应用,我们成功地将信息处理的时间从数小时缩短到了几分钟,极大地提高了信息处理的效率和准确性。这不仅为投资团队提供了实时的市场洞察,也为他们在激烈的市场竞争中赢得了宝贵的时间优势。
三、技术原理
在证券行业,事件驱动策略的核心在于迅速捕捉并分析可能影响市场的重大事件。为了实现这一目标,我们采用了深度学习技术,特别是自然语言处理(NLP)领域的先进技术,以自动化地从文本数据中提取相关信息。
深度学习模型,如BERT、GPT和XLNet,通过在大规模文本数据集上进行预训练,掌握了语言的深层结构和丰富语义。这些模型为信息抽取任务奠定了坚实的基础。然而,为了适应特定的信息需求,如证券市场的事件识别,这些预训练模型需要进行任务特定的微调。在这一过程中,模型会在特定领域的标注数据上进行进一步训练,以提高其在实体识别、关系抽取和事件抽取等任务上的表现。
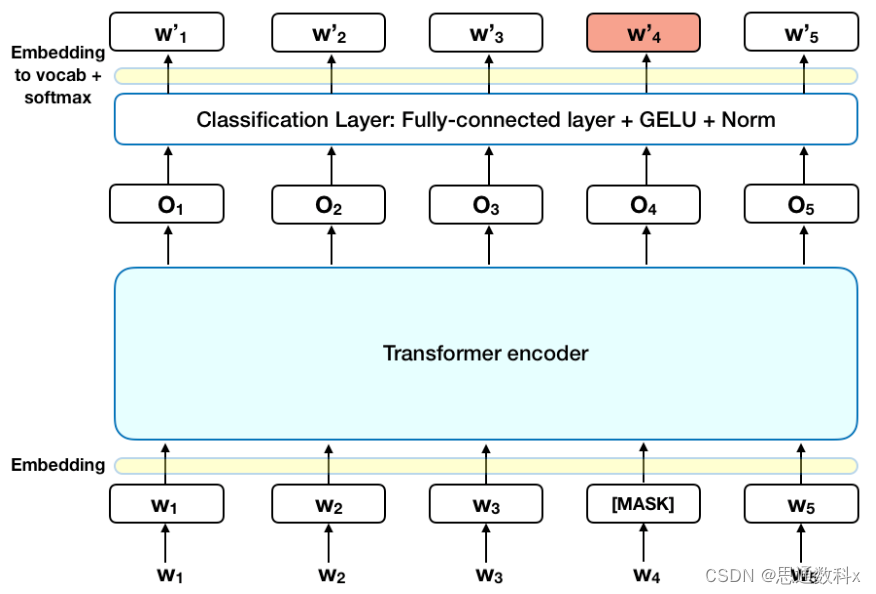
序列标注技术,如条件随机场(CRF)和双向长短时记忆网络(BiLSTM),在实体识别任务中发挥着关键作用。它们能够识别文本中的人名、地名、组织名等实体,并将其与相关事件关联起来。而序列到序列(Seq2Seq)模型,尤其是基于注意力机制的Transformer模型,能够处理更复杂的任务,如将问题转换为答案或摘要,从而理解输入序列的上下文信息。
整个模型的训练过程是端到端的,这意味着从输入到输出的整个过程都在一个统一的框架下进行优化。这种训练方式有助于提升模型的整体性能。在训练过程中,模型的性能会通过准确率、召回率和F1分数等指标进行评估。根据这些评估结果,我们可以对模型进行调整,如调整学习率、优化网络结构或增加训练数据,以进一步提高信息抽取的准确性。
通过这些技术的应用,我们的项目不仅提高了信息处理的效率,还为投资决策提供了实时、准确的数据支持。这使得投资团队能够快速响应市场变化,把握投资机会,从而在竞争激烈的市场中保持领先地位。
四、技术实现
在项目实施过程中,我们选择了一个成熟的NLP平台来辅助我们的信息抽取任务。这个平台提供了一整套工具和服务,使我们能够高效地处理和分析文本数据。以下是我们如何利用这个平台的具体步骤:
- 数据收集:我们首先从多个来源收集了与证券市场相关的文本数据,包括新闻报道、财报、分析师报告和社交媒体帖子。我们确保收集的数据样本覆盖了各种可能的市场事件,以便训练模型能够识别和处理各种情况。
- 数据清洗:在收集到数据后,我们使用平台提供的数据清洗工具来预处理这些数据。这包括去除无关信息、纠正拼写错误、标准化术语等,以确保数据的质量和一致性。
- 样本标注:我们利用平台的在线标注工具对数据进行标注。这个工具支持多种标注类型,如实体、关系和事件。我们确保所有标注者都遵循相同的标准,以保证标注的一致性。为了提高标注质量,我们进行了多轮的标注和校对。
- 样本训练:在数据标注完成后,我们使用平台的机器学习工具来训练模型。我们提取了文本特征,如词性标注、命名实体识别(NER)和依存句法分析,并调整模型参数以优化性能。
- 模型评估:我们通过平台的评估工具来测试模型的性能。我们使用了精确度、召回率和F1分数等指标,并采用交叉验证方法来确保模型的泛化能力。根据评估结果,我们对模型进行了多次迭代,以达到最佳性能。
- 结果预测:一旦模型训练完成并通过评估,我们就将其部署到生产环境中。平台支持一键部署,使得模型可以快速地对新的文本数据进行信息抽取。模型能够自动执行任务,输出结构化的结果,极大地提高了我们的工作效率。

通过这个NLP平台,我们不仅简化了信息抽取的流程,还提高了数据处理的准确性和效率。这个平台的易用性和强大的功能使我们能够专注于数据分析和决策,而不是技术实现的细节。这为我们的项目成功提供了坚实的技术基础。
伪代码示例
为了进一步说明我们如何使用NLP平台的信息抽取功能,下面我将提供一个伪代码示例,展示我们是如何从证券行业的新闻事件中提取关键信息的。请注意,以下伪代码中的输入数据是虚构的,与实际接口说明中的输入示例不同。
# 导入必要的库
import requests# 设置请求头,包含请求密钥
headers = {'secret-id': '你的secret-id','secret-key': '你的secret-key'
}# 准备请求参数
data = {'text': '今日,华泰证券发布财报,显示其第二季度净利润同比增长30%。同时,公司宣布将投资5亿美元于新兴科技领域。','sch': '公司,净利润,投资','modelID': 123 # 假设的模型ID
}# 发送POST请求到NLP平台的信息抽取接口
response = requests.post('https://nlp.stonedt.com/api/extract', headers=headers, json=data)# 解析返回的JSON数据
if response.status_code == 200:json_response = response.json()# 输出抽取结果print("信息抽取结果:")for entity in json_response['result'][0]:print(f"{entity}:")for item in json_response['result'][0][entity]:print(f"- 文本: {item['text']}, 起始位置: {item['start']}, 结束位置: {item['end']}, 准确率: {item['probability']:.2f}")
else:print("请求失败,状态码:", response.status_code)print("错误信息:", response.text)
在这个示例中,我们首先设置了请求头,包含了必要的密钥信息。然后,我们准备了请求参数,包括文本内容、抽取范围和模型ID。接着,我们使用`requests`库发送POST请求到NLP平台的信息抽取接口。最后,我们解析返回的JSON数据,并输出了抽取结果,包括实体文本、在原文中的起始和结束位置以及抽取的准确率。
这个伪代码示例直观地展示了我们如何利用NLP平台的信息抽取功能来处理证券行业的新闻事件,并从中提取关键信息。通过这种方式,我们能够快速地从大量文本数据中提取有价值的信息,为投资决策提供支持。
数据库表结构
在设计数据库表结构以存储接口返回数据时,我们需要考虑数据的组织方式,以便能够高效地查询和分析。以下是一个可能的数据库表结构设计,用于存储从NLP平台接口返回的信息抽取结果。
1. 事件表 (Events)
- event_id: 主键,唯一标识每个事件。
- source: 文本来源,如新闻报道、财报等。
- text: 原始文本内容。
- timestamp: 事件发生的时间戳。
- model_id: 用于信息抽取的模型ID。
2. 实体表 (Entities)
- entity_id: 主键,唯一标识每个实体。
- event_id: 外键,关联到事件表。
- type: 实体类型,如公司、产品、财务指标等。
- text: 实体在文本中的文本表示。
- start_position: 实体在原始文本中的起始位置。
- end_position: 实体在原始文本中的结束位置。
- probability: 实体识别的准确率。
3. 关系表 (Relations)
- relation_id: 主键,唯一标识每个关系。
- source_event_id: 外键,关联到源事件。
- target_event_id: 外键,关联到目标事件。
- relation_type: 关系类型,如合作伙伴、竞争对手等。
- description: 关系的描述性文本。
4. 属性表 (Attributes)
- attribute_id: 主键,唯一标识每个属性。
- entity_id: 外键,关联到实体表。
- name: 属性名称,如发布日期、价格等。
- value: 属性值。
- confidence: 属性值的置信度。
这个数据库设计允许我们存储和关联事件、实体、关系和属性,从而能够全面地理解和分析证券市场中的关键信息。通过这样的结构,我们可以轻松地查询特定实体的所有相关信息,或者追踪特定事件的所有实体和关系。这样的设计也便于后续的数据挖掘和分析工作。
五、项目总结
本项目通过整合先进的自然语言处理技术和机器学习算法,显著提升了证券市场信息处理的效率和准确性。我们的解决方案实现了从多源文本中自动提取关键事件和财务指标,极大缩短了信息处理时间,从数小时缩短至几分钟。这一转变不仅提高了分析师的工作效率,也为他们提供了实时的市场洞察,使投资决策更加迅速和精准。此外,通过实体抽取和关系抽取技术,我们能够深入理解市场动态,为投资者揭示了潜在的投资机会。项目实施结果表明,我们的系统在提高决策质量、增强市场竞争力方面发挥了关键作用,为投资团队在激烈的市场竞争中赢得了宝贵的先机。
六、开源项目(本地部署,永久免费)
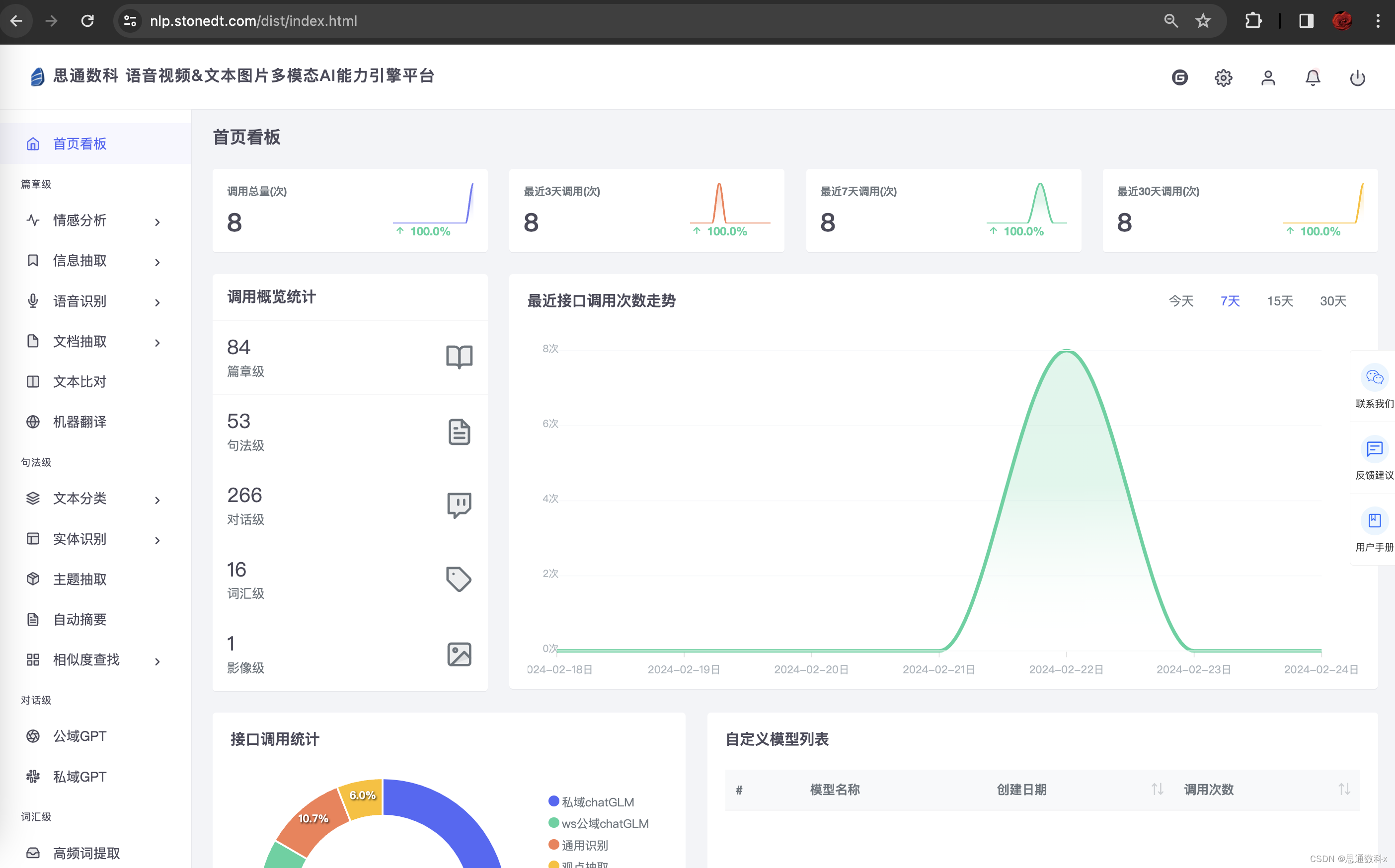
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。
多模态AI能力引擎平台![]() https://gitee.com/stonedtx/free-nlp-api
https://gitee.com/stonedtx/free-nlp-api