文章目录
- 大语言模型LLM分布式框架:PyTorch Lightning框架(LLM系列14)
- 引言
- PyTorch Lightning分布式计算基础
- PyTorch Lightning核心架构概览
- LightningModule与分布式训练的兼容性
- LightningDataModule在分布式数据加载与预处理中的作用
- Trainer类与分布式训练配置
- PyTorch Lightning的分布式特性
- 单机多GPU并行(数据并行)
- 多机多GPU并行
- 后端支持与通信优化
- LLM分布式训练关键技术
- 模型并行化策略
- 层级并行(Layer Parallelism)
- 管道并行(Pipeline Parallelism)
- 参数并行与模型拆分方法
- 数据并行下的负载均衡与内存管理
- 数据分片策略与数据均衡加载
- 动态调整batch size以适应分布式训练
- 分布式训练流程管理
- 启动分布式训练流程的详细步骤
- 故障恢复与检查点保存策略
- PyTorch Lightning在LLM分布式训练中的实践
- 具体应用案例分析
- 分布式训练性能评估与比较
大语言模型LLM分布式框架:PyTorch Lightning框架(LLM系列14)
引言
在当前的自然语言处理领域,大规模语言模型(LLM)已成为推动技术创新的关键驱动力,其在文本生成、语义理解、问答系统等方面取得了显著成果。然而,这类模型通常拥有数十亿乃至上千亿的参数规模,对计算资源的需求急剧增加,单机训练往往难以满足需求。为此,分布式训练技术应运而生,而PyTorch Lightning作为一个轻量级的PyTorch封装库,极大简化了分布式训练的复杂性,使得科研人员能够更专注于模型构建和实验设计,而非底层分布式计算的实现。
PyTorch Lightning分布式计算基础
PyTorch Lightning核心架构概览
PyTorch Lightning提供了一个模块化的编程界面,通过定义LightningModule、LightningDataModule和Trainer三大核心组件,让用户能够以简洁、直观的方式组织模型、数据和训练过程。其核心思想是将模型训练、验证和测试的通用逻辑抽取出来,由Trainer类统一管理,从而大大降低了代码的冗余和复杂性。
LightningModule与分布式训练的兼容性
LightningModule遵循面向对象编程的原则,封装了模型的构建、前向传播、损失函数计算以及反向传播优化过程。在分布式训练场景下,LightningModule自动适应并行环境,无论是单机多GPU还是多机多GPU,只需要少量额外配置,就能无缝对接分布式训练。
LightningDataModule在分布式数据加载与预处理中的作用
LightningDataModule负责数据集的加载、预处理、数据增强等任务,确保数据在分布式环境中能够均匀、高效地分配到各个计算节点,减轻了用户手动处理数据并行化的工作负担。
Trainer类与分布式训练配置
Trainer类是PyTorch Lightning的核心组成部分,它包含了训练、验证、测试全流程的管理逻辑,并提供了一系列便捷的分布式训练配置选项,如选择分布式策略、设置多GPU并行、集成作业调度系统等。
PyTorch Lightning的分布式特性
单机多GPU并行(数据并行)
- DDP (Distributed Data Parallel) 的实现原理:PyTorch Lightning内置了对DDP的支持,通过复制模型并在多个GPU上并行执行,利用AllReduce操作进行梯度聚合,实现数据并行训练。
- 参数同步与梯度聚合机制:在每个训练步骤结束时,DDP自动收集所有GPU上的梯度,并在所有GPU上进行平均,确保模型参数在所有GPU上保持一致。
- 自动混合精度训练支持:PyTorch Lightning还支持混合精度训练,通过在模型的部分层中使用半精度浮点数,既能节约显存,又能提高计算速度。
多机多GPU并行
- 初始化分布式环境与多节点通信设置:用户仅需通过简单的命令行参数或环境变量,即可初始化一个多机多GPU的分布式训练环境,并指定通信后端。
- 使用
Trainer类配置多节点训练参数:在Trainer类的初始化中,通过设置num_nodes、gpus等参数,可以轻松配置多节点训练环境。 - 集成作业调度系统(如Slurm、LSF):PyTorch Lightning与常见的作业调度系统无缝集成,便于在大规模集群上运行分布式训练任务。
后端支持与通信优化
- 支持NCCL、GLOO等分布式通信后端:PyTorch Lightning默认支持NCCL作为高速通信后端,同时也支持GLOO等其他通信库,可根据实际硬件和网络状况选择最合适的通信方案。
- 通信开销的减少策略与节点间同步优化:通过采用高效的通信算法、梯度累积、梯度压缩等技术,有效地降低了分布式训练中的通信开销,提高了训练效率。
LLM分布式训练关键技术
模型并行化策略
层级并行(Layer Parallelism)
层级并行是一种将深度学习模型的层按照一定规则分布在不同GPU或计算节点上的策略。例如,可以将模型的隐藏层横向往划分割,使得每一层在不同的设备上独立运算,然后通过有效的通信方式(如AllReduce)同步各层之间的中间结果。这种并行方式特别适合于具有大量层且每层参数较少的大规模模型,可以有效缓解单个GPU或节点内存不足的问题。
管道并行(Pipeline Parallelism)
管道并行则是将模型结构按照计算流图分成多个连续的子模块或者阶段,这些子模块在不同的设备上顺序执行,形成类似于流水线的操作模式。当一个子模块完成其计算后,会将结果传递给下一个子模块,这样可以突破单个设备的内存限制,允许模型在有限资源条件下进行训练。但需要注意的是,由于数据需要在不同阶段间流转,因此引入了pipeline的延迟,需要采取适当的方法(如微批次、Overlap Communication and Computation)来减小这个影响。
参数并行与模型拆分方法
参数并行主要针对那些参数维度极大的模型,特别是权重矩阵较大的部分,可以通过将参数矩阵拆分成多个块,在不同设备上分别存储和更新。这种方法要求模型的参数可以水平拆分,比如Transformer中的自注意力机制层就适合参数并行。通过合理地将参数分散至多个GPU或节点,可以大幅降低单个设备上的内存压力。
数据并行下的负载均衡与内存管理
数据分片策略与数据均衡加载
在数据并行的情况下,训练数据会被分割成多个分片,分配到各个GPU或节点上独立处理。为了保证训练效率,必须确保每个设备处理的数据量大致相同,避免因负载不均造成的计算资源浪费。这通常需要借助于数据加载器的随机采样策略和数据预处理机制,确保在整个训练过程中达到良好的数据均衡。
动态调整batch size以适应分布式训练
在分布式环境下,batch size的选择既要考虑硬件资源(如显存大小),也要考虑模型结构和优化算法的要求。通过动态调整batch size,可以在不影响模型收敛的前提下,充分利用不同设备的计算能力,防止内存溢出,同时兼顾训练速度和计算资源的有效利用。
分布式训练流程管理
启动分布式训练流程的详细步骤
在PyTorch Lightning中,启动分布式训练通常涉及以下步骤:
- 定义LightningModule,封装模型结构及训练/验证逻辑。
- 创建符合分布式训练需求的Trainer实例,设置诸如
gpus、num_nodes、distributed_backend等参数以启用分布式训练。 - 定义并实例化LightningDataModule,用于管理和加载分布式数据。
- 调用Trainer的
.fit()方法启动训练循环。
故障恢复与检查点保存策略
PyTorch Lightning提供了强大的故障恢复机制,可定期保存模型和优化器的状态,以便在训练过程中遇到任何中断时能够从最近的检查点恢复训练。此外,还可以设置checkpoint回调,自动保存最优模型权重,确保训练过程的稳定性。
PyTorch Lightning在LLM分布式训练中的实践
具体应用案例分析
在实践中,PyTorch Lightning已经成功应用于GPT-3、BERT等大型语言模型的分布式训练。通过对这些模型的分布式训练过程进行详尽解析,可以观察到PyTorch Lightning如何简化训练流程、优化资源分配以及提高训练效率。
分布式训练性能评估与比较
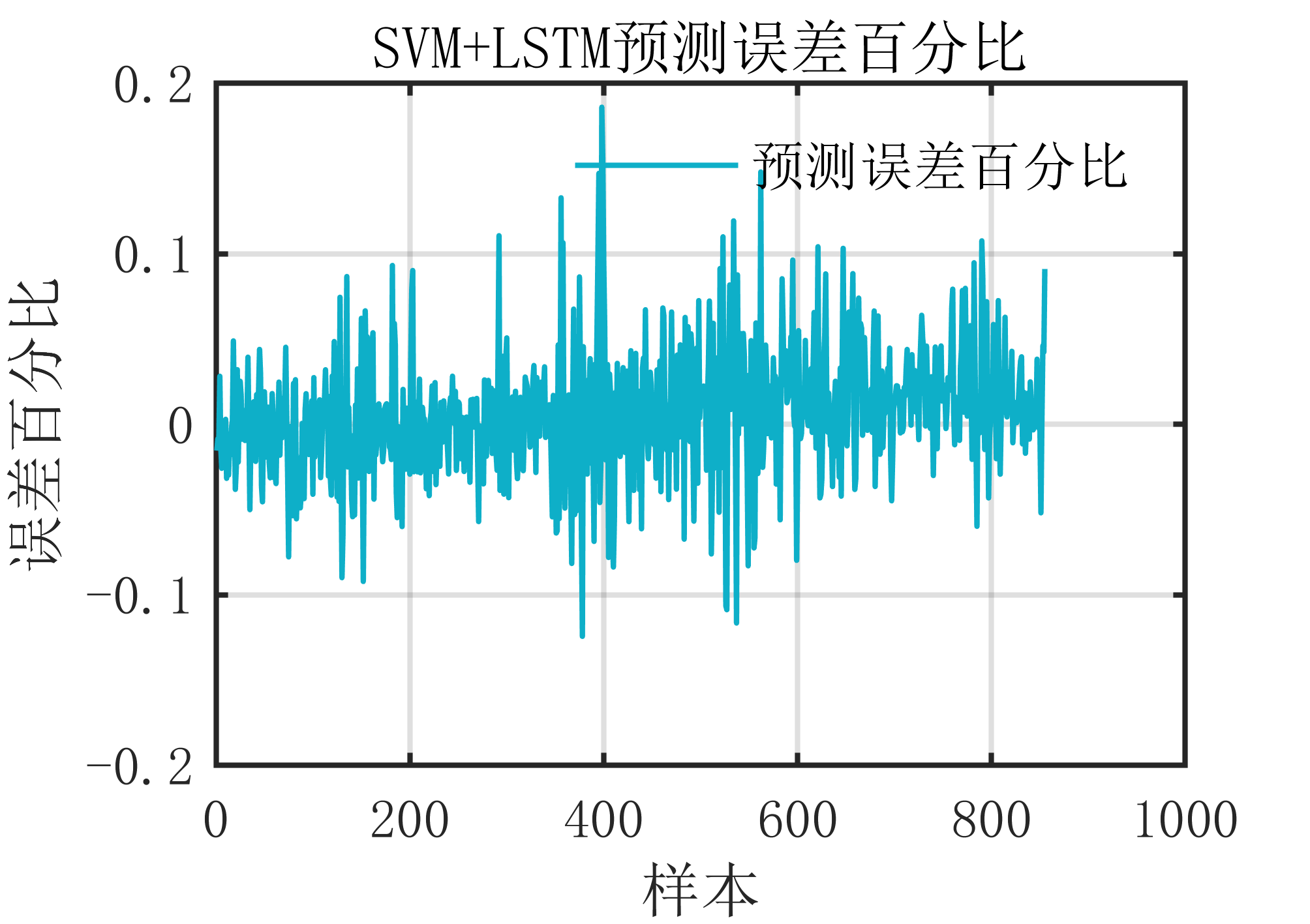
通过对比单机训练与分布式训练的实测数据,我们可以看到PyTorch Lightning在分布式场景下的优势明显,如缩短训练时间、减少单点资源消耗,同时还能维持甚至提升模型训练质量。