K8s常用命令合集
1. 创建资源
一般创建资源会有两种方式:通过文件或者命令创建。
# 通过文件创建一个Deployment
kubectl create -f /path/to/deployment.yaml
cat /path/to/deployment.yaml | kubectl create -f -
# 不过一般可能更常用下面的命令来创建资源
kubectl apply -f /path/to/deployment.yaml# 通过kubectl命令直接创建
kubectl run nginx_app --image=nginx:1.9.1 --replicas=3
kubectl还提供了一些更新资源的命令,比如kubectl edit、kubectl patch和kubectl replace等。
# kubectl edit:相当于先用get去获取资源,然后进行更新,最后对更新后的资源进行apply
kubectl edit deployment/nginx_app# kubectl patch:使用补丁修改、更新某个资源的字段,比如更新某个node
kubectl patch node/node-0 -p '{"spec":{"unschedulable":true}}'
kubectl patch -f node-0.json -p '{"spec": {"unschedulable": "true"}}'# kubectl replace:使用配置文件来替换资源
kubectl replace -f /path/to/new_nginx_app.yaml
2. 查看资源
获取不同种类资源的信息。
# 一般命令的格式会如下:
kubectl get <resource_type>
# 比如获取K8s集群下pod的信息
kubectl get pod
# 更加详细的信息
kubectl get pod -o wide
# 指定资源的信息,格式:kubectl get <resource_type>/<resource_name>,比如获取deployment nginx_app的信息
kubectl get deployment/nginx_app -o wide
# 也可以对指定的资源进行格式化输出,比如输出格式为json、yaml等
kubectl get deployment/nginx_app -o json
# 还可以对输出结果进行自定义,比如对pod只输出容器名称和镜像名称
kubectl get pod httpd-app-5bc589d9f7-rnhj7 -o custom-columns=CONTAINER:.spec.containers[0].name,IMAGE:.spec.containers[0].image
# 获取某个特定key的值还可以输入如下命令得到,此目录参照go template的用法,且命令结尾'\n'是为了输出结果换行
kubectl get pod httpd-app-5bc589d9f7-rnhj7 -o template --template='{{(index spec.containers 0).name}}{{"\n"}}'
# 还有一些可选项可以对结果进行过滤,这儿就不一一列举了,如有兴趣,可参照kubectl get --help说明
3. 部署命令集
部署命令包括资源的运行管理命令、扩容和缩容命令和自动扩缩容命令。
3.1 rollout命令
管理资源的运行,比如deployment、DeamonSet、StatefulSet等资源。
- 动态升级:通过逐个容器替代升级的方式来实现无中断的服务升级:
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
- 查看部署状态:比如更新deployment/nginx_app中容器的镜像后查看其更新的状态。
kubectl set image deployment/nginx_app nginx=nginx:1.9.1
kubectl rollout status deployment/nginx_app
- 资源的暂停及恢复:发出一次或多次更新前暂停一个 Deployment,然后再恢复它,这样就能在Deployment暂停期间进行多次修复工作,而不会发出不必要的 rollout。
# 暂停
kubectl rollout pause deployment/nginx_app
# 完成所有的更新操作命令后进行恢复
kubectl rollout resume deployment/nginx_app
- 回滚:如上对一个Deployment的image做了更新,但是如果遇到更新失败或误更新等情况时可以对其进行回滚。
# 回滚之前先查看历史版本信息
kubectl rollout history deployment/nginx_app
# 回滚
kubectl rollout undo deployment/nginx_app
# 当然也可以指定版本号回滚至指定版本
kubectl rollout undo deployment/nginx_app --to-revision=<version_index>
3.2 scale命令
对一个Deployment、RS、StatefulSet进行扩/缩容。
# 扩容
kubectl scale deployment/nginx_app --replicas=5
# 如果是缩容,把对应的副本数设置的比当前的副本数小即可
# 另外,还可以针对当前的副本数目做条件限制,比如当前副本数是5则进行缩容至副本数目为3
kubectl scale --current-replicas=5 --replicas=3 deployment/nginx_app
3.3 autoscale命令
通过创建一个autoscaler,可以自动选择和设置在K8s集群中Pod的数量。
# 基于CPU的使用率创建3-10个pod
kubectl autoscale deployment/nginx_app --min=3 --max=10 --cpu_percent=80
3.4 NotePort
内部地址设置成外部可访问,将ClusterIP改为NotePort
# 查看type
kubectl get svc
# 修改文件
kubectl edit svc svc_name
4. 集群管理命令
4.1 cordon & uncordon命令
设置是否能够将pod调度到该节点上。
# 不可调度
kubectl cordon node-0# 当某个节点需要维护时,可以驱逐该节点上的所有pods(会删除节点上的pod,并且自动通过上面命令设置
# 该节点不可调度,然后在其他可用节点重新启动pods)
kubectl drain node-0
# 待其维护完成后,可再设置该节点为可调度
kubectl uncordon node-0
4.2 taint命令
目前仅能作用于节点资源,一般这个命令通常会结合pod的tolerations字段结合使用,对于没有设置对应toleration的pod是不会调度到有该taint的节点上的,这样就可以避免pod被调度到不合适的节点上。一个节点的taint一般会包括key、value和effect(effect只能在NoSchedule, PreferNoSchedule, NoExecute中取值)。
# 设置taint
kubecl taint nodes node-0 key1=value1:NoSchedule
# 移除taint
kubecl taint nodes node-0 key1:NoSchedule-
如果pod想要被调度到上述设置了taint的节点node-0上,则需要在该pod的spec的tolerations字段设置:
tolerations:
- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"# 或者
tolerations:
- key: "key1"operator: "Exists"effect: "NoSchedule"
4.3 标签管理
# 查询节点标签
kubectl get node --show-labels# 添加标签
kubectl label nodes kube-node label_name=label_value# 查询标签
kubectl get node -a -l test=true# 删除标签
# 在命令行最后指定Label的key名并与一个减号相连即可
kubectl label nodes 192.168.1.1 test-# 修改标签
# 或者直接edit
kubectl label nodes 192.168.1.1 test=false --overwrite
5. 其它
# 查看deployment名字
kubectl get deployment
# 映射端口允许外部访问
kubectl expose deployment/nginx_app --type='NodePort' --port=80 --target-port=8000
#为nginx deployment创建服务,该服务在端口80上运行,并连接到容器的8000端口上
# 然后通过kubectl get services -o wide来查看被随机映射的端口
# 如此就可以通过node的外部IP和端口来访问nginx服务了# 转发本地端口访问Pod的应用服务程序
kubectl port-forward nginx_app_pod_0 8090:80
# 如此,本地可以访问:curl -i localhost:8090# 在创建或启动某些资源的时候没有达到预期结果,可以使用如下命令先简单进行故障定位
kubectl describe deployment/nginx_app
kubectl logs nginx_pods
kubectl exec nginx_pod -c nginx-app <command># 集群内部调用接口(比如用curl命令),可以采用代理的方式,根据返回的ip及端口作为baseurl
kubectl proxy &# 查看K8s支持的完整资源列表
kubectl api-resources# 查看K8s支持的api版本
kubectl api-versions# 查看命令详细帮助
kubectl explain pod# 查看报错
kubectl log pod-name -c error_contrainer_name#获取dashboard的token
kubectl -n kube-system get secret | grep kubernetes-dashboard-token
kubectl describe secret kubernetes-dashboard-token-797gr -n kube-system#删除所有pod
kubectl get pod -A |grep -v NAMESPACE | awk '{print $1,$2}' | xargs -I {} echo "kubectl delete po -n {}" >1.ss ; sh 1.ss
5.1报错解决步骤
# 查看状态发现错误
kubectl get pod
# 查看详细信息
kubectl describe pod pod_name
# 观察pod中哪个容器报错
kubectl log pod-name -c error_contrainer_name
6.pod模板
pod.yml# 采用哪种版本
apiVersion: v1
# 采用那种类型
kind: Pod
# 元数据类型
metadata: # 名称name: myapp-pod# 名空间namespace: default# 标签labels:app: myappversion: v1
# 运行容器的详细信息,可通过kubectl explain pod.spec查看
spec:containers:- name: appimage: image-name- name: testimage: image-name# 运行在同一个pasue,故端口不能重复。
7.k8s集群扩容缩容
7.1缩容
# 查看node节点
kubectl get nodes# 如果节点有pod,可以给该节点设置污点为NoExecute,把pod转移到其他node节点
kubectl taint nodes node1 key1=value1:NoExecute#还可以使用cordon(停止调度)、drain(驱逐)、uncordon(恢复),将删除节点上的pod迁移至集群中的其他节点上(在master节点操作)
kubectl cordon k8s-node2
kubectl drain k8s-node2
kubectl uncordon k8s-node2# 删除节点
kubectl delete nodes k8s-node1# 在被删除的node节点中清空集群数据信息
kubeadm resetcordon、drain、uncordon命令
7.2扩容
# 查看集群中的token,返回中有加入节点的命令
kubeadm token create --print-join-command# 添加node节点进入集群中
kubeadm join 192.168.16.10 --token XXXXXXX8、更改calico地址池
开始更改
1.添加新的IP池:
1 calicoctl create -f -<<EOF2 apiVersion: projectcalico.org/v33 kind: IPPool4 metadata:5 name: new-pool6 spec:7 cidr: 10.0.0.0/168 ipipMode: Always9 natOutgoing: true
10 EOF
我们现在应该有两个启用的IP池,我们可以在运行时看到,查看命令:calicoctl get ippool -o wide
1 NAME CIDR NAT IPIPMODE DISABLED
2 default-ipv4-ippool 192.168.0.0/16 true Always false
3 new-pool 10.0.0.0/16 true Always false
2.禁用旧的IP池,首先将IP池定义保存到磁盘:
1 calicoctl get ippool -o yaml > pool.yaml
pool.yaml 文件内容:
1 apiVersion: projectcalico.org/v32 items:3 - apiVersion: projectcalico.org/v34 kind: IPPool5 metadata:6 name: default-ipv4-ippool7 spec:8 cidr: 192.0.0.0/169 ipipMode: Always
10 natOutgoing: true
11 - apiVersion: projectcalico.org/v3
12 kind: IPPool
13 metadata:
14 name: new-pool
15 spec:
16 cidr: 10.0.0.0/16
17 ipipMode: Always
18 natOutgoing: true
注意:已经编辑了一些额外的特定于群集的信息以提高可读性,编辑文件,添加disabled: true到default-ipv4-ippoolIP池:
1 apiVersion: projectcalico.org/v3
2 kind: IPPool
3 metadata:
4 name: default-ipv4-ippool
5 spec:
6 cidr: 192.0.0.0/16
7 ipipMode: Always
8 natOutgoing: true
9 disabled: true
应用更改:
1 calicoctl apply -f pool.yaml
我们可以看到产生了一下变化,查看命令:
1 calicoctl get ippool -o wide
2 NAME CIDR NAT IPIPMODE DISABLED
3 default-ipv4-ippool 192.168.0.0/16 true Always true
4 new-pool 10.0.0.0/16 true Always false
使用禁用池中的IP重新创建所有现有工作负载。在此示例中,kube-dns是Calico联网的唯一工作负载:
1 kubectl delete pod -n kube-system kube-dns-6f4fd4bdf-8q7zp
通过运行以下命令检查新工作负载现在是否在新IP池中具有地址:
1 calicoctl get wep --all-namespaces
2 NAMESPACE WORKLOAD NODE NETWORKS INTERFACE
3 kube-system kube-dns-6f4fd4bdf-8q7zp vagrant 10.0.24.8/32 cali800a63073ed
删除旧的IP池:
1 calicoctl delete pool default-ipv4-ippool
9、kubelet配置资源预留
在k8s集群中,默认情况下 Pod 能够使用节点全部可用容量,同样就会伴随一个新的问题,pod消耗的内存会挤占掉系统服务本身的资源,这就好比我们在宿主机上运行java服务一样,会出现java程序将宿主机上的资源(内存、cpu)耗尽,从而导致系统登陆不上或者卡顿现象。同理在k8s集群中也会出现类似的问题,从而也会导致一系列不可控的故障产生。因此为系统守护进程预留出部分资源,也是很有必要的。
Kubelet Node Allocatable用来为Kube组件和System进程预留资源,从而保证当节点出现满负荷时也能保证Kube和System进程有足够的资源。目前支持cpu, memory, ephemeral-storage三种资源预留。
计算方式
Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
其中:
Node Capacity:Node的所有硬件资源,kube-reserved是给kube组件预留的资源
Kube-reserved:kube 组件预留的资源
system-reserved:给system进程预留的资源
eviction-threshold(阈值):kubelet eviction(收回)的阈值设定
只有allocatable才是真正scheduler调度Pod时的参考值(保证Node上所有Pods的request resource不超过Allocatable) ,关系图如下:
在这里插入图片描述
配置方式(基于yum安装)
我们先通过 kubectl describe node 命令查看节点可分配资源的数据:
kubectl describe nodes k8s-m1
...
Capacity:cpu: 8ephemeral-storage: 206292644Kihugepages-1Gi: 0hugepages-2Mi: 0memory: 15731900Kipods: 110
Allocatable:cpu: 8ephemeral-storage: 190119300396hugepages-1Gi: 0hugepages-2Mi: 0memory: 15629500Kipods: 110
...
可以看到其中有 Capacity 与 Allocatable 两项内容,其中的 Allocatable 就是节点可被分配的资源,我们这里没有配置资源预留,所以默认情况下 Capacity 与 Allocatable 的值基本上是一致的。
配置资源预留
比如我们现在需要为系统预留一定的资源,我们可以使用如下的几个 kubelet 参数来进行配置:
--enforce-node-allocatable=pods
--kube-reserved=memory=...
--system-reserved=memory=...
--eviction-hard=...
这里我们暂时不设置对应的 cgroup,比如我们这里先只对 master1 节点添加资源预留,我们可以直接修改 /var/lib/kubelet/config.yaml 文件来动态配置 kubelet,添加如下所示的资源预留配置:
......
enforceNodeAllocatable:
pods
kubeReserved: # 配置 kube 资源预留cpu: 500mmemory: 1Giephemeral-storage: 1Gi
systemReserved: # 配置系统资源预留memory: 1Gi
evictionHard: # 配置硬驱逐阈值memory.available: "300Mi"nodefs.available: "10%"
在这里插入图片描述
修改完成后,重启 kubelet,启动完成后重新对比 Capacity 及 Allocatable 的值:
kubectl describe nodes k8s-m1...
Capacity:cpu: 8ephemeral-storage: 206292644Kihugepages-1Gi: 0hugepages-2Mi: 0memory: 15731900Kipods: 110
Allocatable:cpu: 7500mephemeral-storage: 189045558572hugepages-1Gi: 0hugepages-2Mi: 0memory: 13327548Kipods: 110
...
仔细对比可以发现其中的 Allocatable的值恰好是 Capacity 减去上面我们配置的预留资源的值:
allocatale = capacity - kube_reserved - system_reserved - eviction_hard内存: 13327548Ki = 15731900Ki - 1*1024*1024Ki - 1*1024*1024Ki - 300*1024Ki
CPU: 7500m = 8000m - 500m (单位为m是以CPU的时间分片计量的,1C为1000m)
再通过查看 kubepods.slice(systemd 驱动是以 .slice 结尾)cgroup 中对节点上所有 Pod 内存的限制,该值决定了 Node 上所有的 Pod 能使用的资源上限:
cat /sys/fs/cgroup/memory/kubepods.slice/memory.limit_in_bytes
13961981952 #单位是byte
得到的 Pod 资源使用上限为:
13961981952 Bytes = 13634748 Ki = Allocatable(13327548 Ki) + eviction_hard(300*1024Ki) # 13961981952 / 1024 = 136347481
也可以通过计算验证我们的配置是正确的:
kubepods.slice/memory.limit_in_bytes = capacity - kube_reserved - system_reserved
Eviction 与 OOM
eviction 是指 kubelet 对该节点上的 Pod 进行驱逐,OOM 是指 cgroup 对进程进行 kill。
kubelet 对 Pod 进行驱逐时,是根据 --eviction-hard 参数,比如该参数如果设置了 memory.available<20%,那么当主机的内存使用率达到80%时,kubelet 便会对Pod进行驱逐。但是,–eviction-hard=memory.available<20% 不会对/sys/fs/cgroup/memory/kubepods.slice/memory.limit_in_bytes 的值产生影响,因为kubepods.slice/memory.limit_in_bytes = capacity - kube-reserved - system-reserved,换句话说,Pod 的内存使用量总和是可以超过80%的,且不会被 OOM-kill,只会被 eviction。
kubernetes 对 Pod 的驱逐机制如下(其实就是 QoS 章节的定义):
首先驱逐没有设置资源限制的 Pod
然后驱逐资源上限和资源下限不一样的 Pod
最后驱逐资源上限等资源下限的Pod
可分配约束
前面我们在配置资源预留的时候,其中有一个 enforceNodeAllocatable 配置项(–enforce-node-allocatable),该配置项的帮助信息为:
--enforce-node-allocatable strings A comma separated list of levels of node allocatable enforcement to be enforced by kubelet. Acceptable options are'none', 'pods', 'system-reserved', and 'kube-reserved'. If the latter two options are specified, '--system-reserved-cgroup' and '--kube-reserved-cgroup' must also be set, respectively. If 'none' is specified, no additional options should be set. See https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/ for more details. (default [pods]) (DEPRECATED: This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.)
kubelet 默认对 Pod 执行 Allocatable 可分配约束,如果所有 Pod 的总用量超过了 Allocatable,那么驱逐 Pod 的措施将被执行,我们可通过设置 kubelet --enforce-node-allocatable 标志值为 pods 控制这个措施。
此外我们还可以通过该标志来同时指定 kube-reserved 和 system-reserved 值,可以让 kubelet 强制实施 kube-reserved 和 system-reserved 约束,不过需要注意,如果配置了 kube-reserved 或者 system-reserved 约束,那么需要对应设置 --kube-reserved-cgroup 或者 --system-reserved-cgroup 参数。
如果设置了对应的 --system-reserved-cgroup 和 --kube-reserved-cgroup 参数,Pod 能实际使用的资源上限是不会改变,但系统进程与 kube 进程也会受到资源上限的限制,如果系统进程超过了预留资源,那么系统进程会被 cgroup 杀掉。但是如果不设这两个参数,那么系统进程就可以使用超过预留的资源上限。
所以如果要为系统预留和 kube 预留配置 cgroup,则需要非常小心,如果执行了 kube-reserved 约束,那么 kubelet 就不能出现突发负载用光所有可用资源,不然就会被杀掉。system-reserved 可以用于为诸如 sshd、udev 等系统守护进程争取资源预留,但是如果执行 system-reserved 约束,那么可能因为某些原因导致节点上的关键系统服务 CPU 资源短缺或因为内存不足而被终止,所以如果不是自己非常清楚如何配置,最好别配置 cgroup 约束,如果需要自行配置,可以参考第一期的资源预留文档进行相关操作。
因此,我们强烈建议用户使用 enforce-node-allocatable 默认配置的 pods 即可,并为系统和 kube 进程预留出适当的资源,以保持整体节点的可靠性,不需要进行 cgroup 约束,除非操作人员对系统非常了解。
10、docker、ctr、crictl命令区别
10.1命令区别
| 命令 | docker | ctr(containerd) | crictl(kubernetes) | |
|---|---|---|---|---|
| 查看运行的容器 | docker ps | ctr task ls/ctr container ls | crictl ps | |
| 查看镜像 | docker images | ctr image ls | crictl images | |
| 查看容器日志 | docker logs | 无 | crictl logs | |
| 查看容器数据信息 | docker inspect | ctr container info | crictl inspect | |
| 查看容器资源 | docker stats | 无 | crictl stats | |
| 启动/关闭已有的容器 | docker start/stop | ctr task start/kill | crictl start/stop | |
| 运行一个新的容器 | docker run | ctr run | 无(最小单元为pod) | |
| 修改镜像标签 | docker tag | ctr image tag | 无 | |
| 创建一个新的容器 | docker create | ctr container create | crictl create | |
| 导入镜像 | docker load | ctr image import | 无 | |
| 导出镜像 | docker save | ctr image export | 无 | |
| 删除容器 | docker rm | ctr container rm | crictl rm | |
| 删除镜像 | docker rmi | ctr image rm | crictl rmi | |
| 拉取镜像 | docker pull | ctr image pull | ctictl pull | |
| 推送镜像 | docker push | ctr image push | 无 | |
| 在容器内部执行命令 | docker exec | 无 | crictl exec |
10.2特别操作
清空不用的容器
docker image prune
crictl rmi --prune
10.3docker镜像转str
docker save -o o.tar tensorflow/tensorflow:2.2.3-gpu-py3
ctr导入镜像 不支持 build,commit 镜像
ctr -n k8s.io i import o.tar
ctr -n default i import o.tar
11、deployment模板
kind: Deployment
apiVersion: apps/v1
metadata:labels:run: test-config-servername: test-config-server #名称namespace: test #名空间
spec:replicas: 3 #副本数revisionHistoryLimit: 10selector:matchLabels:run: test-config-servertemplate:metadata:labels:run: test-config-serverspec:nodeSelector:noderole: test #节点标签选择containers:- name: test-config-serverimage: registry.paas:$version #镜像名称imagePullPolicy: Always readinessProbe: #监控检查配置httpGet: path: /test/healthport: 18080initialDelaySeconds: 60failureThreshold: 3livenessProbe:httpGet:path: /test/healthport: 18080initialDelaySeconds: 60failureThreshold: 3resources: #cpu和内存限制limits: memory: 2048Micpu: 500mrequests:memory: 1024Micpu: 250m ports:- containerPort: 18080protocol: TCPvolumeMounts: #目录挂载- mountPath: /root/config name: configserver- mountPath: /etc/add-hostsname: test-hostsreadOnly: truevolumes:- name: configserverhostPath:path: /root/configtype: Directory- configMap: #使用test-host的configmapitems:- key: test-hostspath: test-hostsname: coredns-test-hostsname: test-hosts imagePullSecrets:- name: regsecret
12、configmap模板
kind: ConfigMap
apiVersion: apps/v1
metadata:name: test-hosts #名称namespace: test
data: customer-host:#
13、server模板
apiVersion: v1
kind: Service
metadata:name: test-config-servernamespace: test
spec:clusterIP: 10.233.9.231ports:- name: httpport: 28080protocol: TCPtargetPort: 28080nodePort: 31362selector:app: test-config-serversessionAffinity: Nonetype: NodePort
14、K8S线上集群排查,实测排查Node节点NotReady异常状态
在分析 NotReady 状态之前,我们首先需要了解在 k8s 中 Pod 的状态都有哪些。并且每个状态都表示什么含义,不同状态是很直观的显示出当前 Pod 所处的创建信息。
为了避免大家对 Node 和 Pod 的概念混淆,先简单描述下两者之间的关系(引用一张 K8S 官方图)。
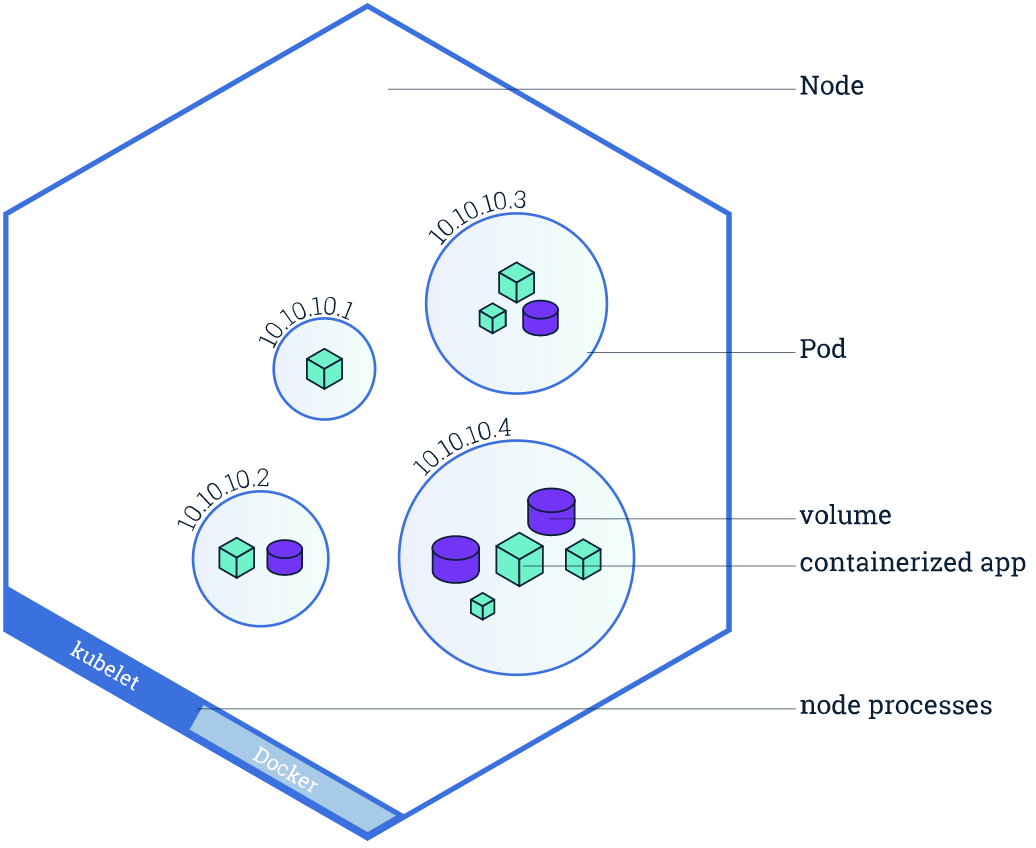
从图中很直观的显示出最外面就是 Node 节点,而一个 Node 节点中是可以运行多个 Pod 容器,再深入一层就是每个 Pod 容器可以运行多个实例 App 容器。
因此关于本篇文章所阐述的 Node 节点不可用,就会直接导致 Node 节点中所有的容器不可用。
毫无疑问,Node 节点是否健康,直接影响该节点下所有的实例容器的健康状态,直至影响整个 K8S 集群。
那么如何解决并排查 Node 节点的健康状态?不急,我们先来聊聊关于关于 Pod 的生命周期状态。
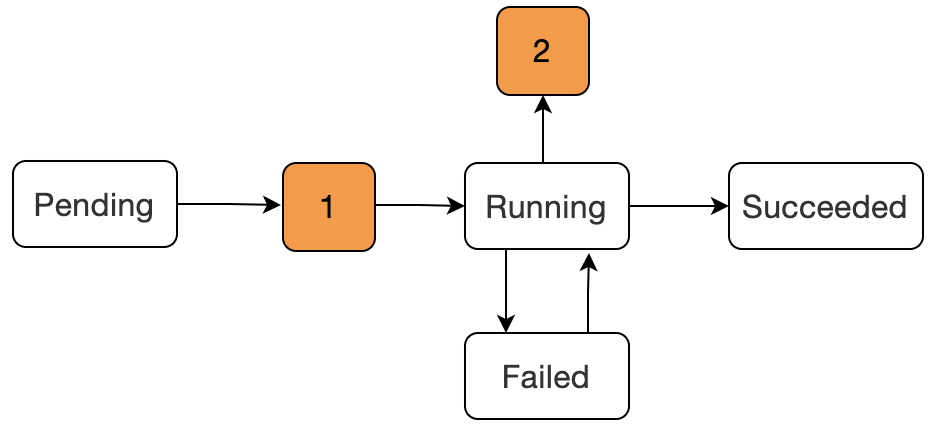
Pending:该阶段表示已经被 Kubernetes 所接受,但是容器还没有被创建,正在被 kube 进行资源调度。1:图中数字 1 是表示在被 kube 资源调度成功后,开始进行容器的创建,但是在这个阶段是会出现容器创建失败的现象Waiting或ContainerCreating:这两个原因就在于容器创建过程中镜像拉取失败,或者网络错误容器的状态就会发生转变。Running:该阶段表示容器已经正常运行。Failed:Pod 中的容器是以非 0 状态(非正常)状态退出的。2:阶段 2 可能出现的状态为CrashLoopBackOff,表示容器正常启动但是存在异常退出。Succeeded:Pod 容器成功终止,并且不会再在重启。
上面的状态只是 Pod 生命周期中比较常见的状态,还有一些状态没有列举出来。
这。。。状态有点多。休息 3 秒钟
不过话又说回来,Pod 的状态和 Node 状态是一回事吗?嗯。。。其实并不完全是一回事。
但是当容器服务不可用时,首先通过 Pod 的状态去排查是非常重要的。那么问题来了,如果 Node 节点服务不可用,Pod 还能访问吗?
答案是:不能。
因此排查Pod的健康状态的意义就在于,是什么原因会导致Node节点服务不可用,因此这是一项非常重要的排查指标。
三,业务回顾
由于本人的工作是和物联网相关的,暂且我们假设 4 台服务器(假设不考虑服务器本身性能问题,如果是这个原因那最好是升级服务器),其中一台做 K8S-Master 搭建,另外 3 台机器做 Worker 工作节点。
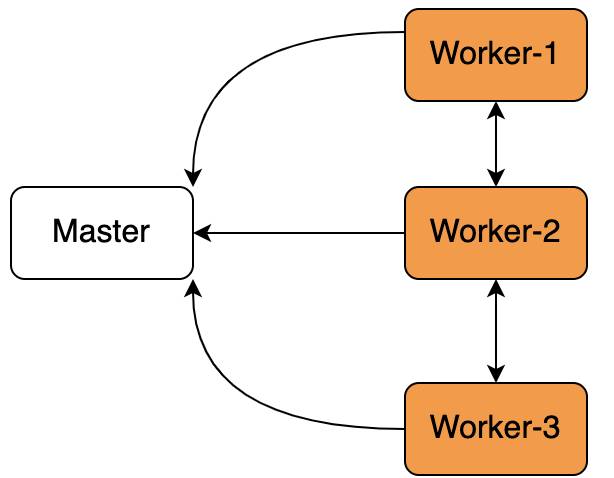
每个 worker 就是一个 Node 节点,现在需要在 Node 节点上去启动镜像,一切正常 Node 就是ready状态。

但是过了一段时间后,就成这样了

这就是我们要说的 Node 节点变成 NotReady 状态。
四,问题刨析
4.1 问题分析
再回到我们前面说到问题,就是 Node 节点变成 NotReady 状态后,Pod 容器是否还成正常运行。

图中用红框标示的就是在节点edgenode上,此时 Pod 状态已经显示为Terminating,表示 Pod 已经终止服务。
接下来我们就分析下 Node 节点为什么不可用。
(1)首先从服务器物理环境排查,使用命令df -m查看磁盘的使用情况

或者直接使用命令free查看

磁盘并没有溢出,也就是说物理空间足够。
(2)接着我们再查看下 CPU 的使用率,命令为:top -c (大写P可倒序)

CPU 的使用率也是在范围内,不管是在物理磁盘空间还是 CPU 性能,都没有什么异常。那 Node 节点怎么就不可用了呢?而且服务器也是正常运行中。
(3)不慌,还有一项可以作为排查的依据,那就是使用 kube 命令 describe 命令查看 Node 节点的详细日志。完整命令为:
kubectl describe node <节点名称>,那么图中 Node 节点如图:

哎呀,好像在这个日志里面看到了一些信息描述,首先我们先看第一句:Kubelet stoped posting node status,大致的意思是 Kubelet 停止发送 node 状态了,再接着Kubelet never posted node status意思为再也收不到 node 状态了。
查看下 Kubelet 是否在正常运行,是使用命令:
systemctl status kubelet,如果状态为 Failed,那么是需要重启下的。但如果是正常运行,请继续向下看。
分析一下好像有点眉目了,Kubelet 为什么要发送 node 节点的状态呢?这就抛出了关于 Pod 的另一个知识点,请耐心向下看。
五,Pod 健康检测 PLEG
根据我们最后面分析的情形,似乎是 node 状态再也没有收到上报,导致 node 节点不可用,这就引申出关于 Pod 的生命健康周期。
PLEG全称为:Pod Lifecycle Event Generator:Pod 生命周期事件生成器。
简单理解就是根据 Pod 事件级别来调整容器运行时的状态,并将其写入 Pod 缓存中,来保持 Pod 的最新状态。
在上述图中,看出是 Kubelet 在检测 Pod 的健康状态。Kubelet 是每个节点上的一个守护进程,Kubelet 会定期去检测 Pod 的健康信息,先看一张官方图。
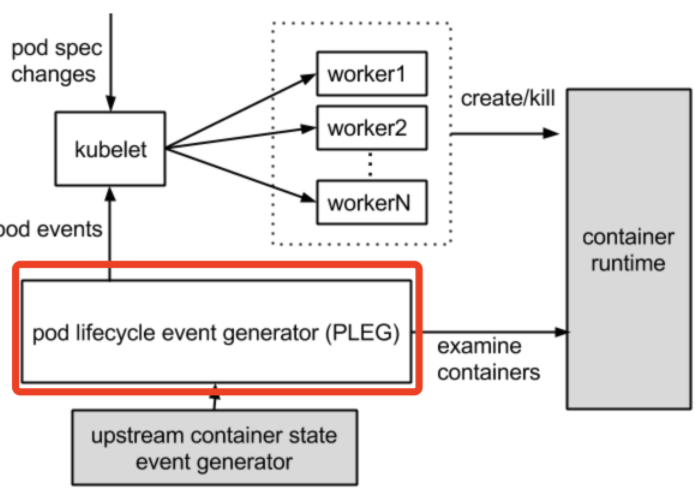
PLEG去检测运行容器的状态,而 kubelet 是通过轮询机制去检测的。
分析到这里,似乎有点方向了,导致 Node 节点变成 NotReady 状态是和 Pod 的健康状态检测有关系,正是因为超过默认时间了,K8S 集群将 Node 节点停止服务了。
那为什么会没有收到健康状态上报呢?我们先查看下在 K8S 中默认检测的时间是多少。
在集群服务器是上,进入目录:/etc/kubernetes/manifests/kube-controller-manager.yaml,查看参数:
–node-monitor-grace-period=40s(node驱逐时间)–node-monitor-period=5s(轮询间隔时间)
上面两项参数表示每隔 5 秒 kubelet 去检测 Pod 的健康状态,如果在 40 秒后依然没有检测到 Pod 的健康状态便将其置为 NotReady 状态,5 分钟后就将节点下所有的 Pod 进行驱逐。
官方文档中对 Pod 驱逐策略进行了简单的描述,https://kubernetes.io/zh/docs/concepts/scheduling-eviction/eviction-policy/

kubelet 轮询检测 Pod 的状态其实是一种很消耗性能的操作,尤其随着 Pod 容器的数量增加,对性能是一种严重的消耗。
在 GitHub 上的一位小哥对此也表示有自己的看法,原文链接为:
https://github.com/fabric8io/kansible/blob/master/vendor/k8s.io/kubernetes/docs/proposals/pod-lifecycle-event-generator.md
到这里我们分析的也差不多了,得到的结论为:
- Pod 数量的增加导致 Kubelet 轮询对服务器的压力增大,CPU 资源紧张
- Kubelet 轮询去检测 Pod 的状态,就势必受网络的影响
- Node 节点物理硬件资源限制,无法承载较多的容器
// 需要重启docker
sudo systemctl restart docker// 需要重启kubelet
sudo systemctl restart kubelet
但是如果条件允许的情况下,最好是从硬件方面优化。
- 提高 Node 节点的物理资源
- 优化 K8S 网络环境
kubectl 操作的简短描述和普通语法:
| 操作 | 语法 | 描述 |
|---|---|---|
alpha | kubectl alpha SUBCOMMAND [flags] | 列出与 alpha 特性对应的可用命令,这些特性在 Kubernetes 集群中默认情况下是不启用的。 |
annotate | `kubectl annotate (-f FILENAME | TYPE NAME |
api-resources | kubectl api-resources [flags] | 列出可用的 API 资源。 |
api-versions | kubectl api-versions [flags] | 列出可用的 API 版本。 |
apply | kubectl apply -f FILENAME [flags] | 从文件或 stdin 对资源应用配置更改。 |
attach | kubectl attach POD -c CONTAINER [-i] [-t] [flags] | 挂接到正在运行的容器,查看输出流或与容器(stdin)交互。 |
auth | kubectl auth [flags] [options] | 检查授权。 |
autoscale | `kubectl autoscale (-f FILENAME | TYPE NAME |
certificate | kubectl certificate SUBCOMMAND [options] | 修改证书资源。 |
cluster-info | kubectl cluster-info [flags] | 显示有关集群中主服务器和服务的端口信息。 |
completion | kubectl completion SHELL [options] | 为指定的 Shell(Bash 或 Zsh)输出 Shell 补齐代码。 |
config | kubectl config SUBCOMMAND [flags] | 修改 kubeconfig 文件。有关详细信息,请参阅各个子命令。 |
convert | kubectl convert -f FILENAME [options] | 在不同的 API 版本之间转换配置文件。配置文件可以是 YAML 或 JSON 格式。注意 - 需要安装 kubectl-convert 插件。 |
cordon | kubectl cordon NODE [options] | 将节点标记为不可调度。 |
cp | kubectl cp <file-spec-src> <file-spec-dest> [options] | 从容器复制文件、目录或将文件、目录复制到容器。 |
create | kubectl create -f FILENAME [flags] | 从文件或 stdin 创建一个或多个资源。 |
delete | `kubectl delete (-f FILENAME | TYPE [NAME |
describe | `kubectl describe (-f FILENAME | TYPE [NAME_PREFIX |
diff | kubectl diff -f FILENAME [flags] | 在当前起作用的配置和文件或标准输之间作对比 (BETA) |
drain | kubectl drain NODE [options] | 腾空节点以准备维护。 |
edit | `kubectl edit (-f FILENAME | TYPE NAME |
events | kubectl events | 列举事件。 |
exec | kubectl exec POD [-c CONTAINER] [-i] [-t] [flags] [-- COMMAND [args...]] | 对 Pod 中的容器执行命令。 |
explain | kubectl explain TYPE [--recursive=false] [flags] | 获取多种资源的文档。例如 Pod、Node、Service 等。 |
expose | `kubectl expose (-f FILENAME | TYPE NAME |
get | `kubectl get (-f FILENAME | TYPE [NAME |
kustomize | `kubectl kustomize[flags] [options] | 列出从 kustomization.yaml 文件中的指令生成的一组 API 资源。参数必须是包含文件的目录的路径,或者是 git 存储库 URL,其路径后缀相对于存储库根目录指定了相同的路径。 |
label | `kubectl label (-f FILENAME | TYPE NAME |
logs | kubectl logs POD [-c CONTAINER] [--follow] [flags] | 打印 Pod 中容器的日志。 |
options | kubectl options | 全局命令行选项列表,这些选项适用于所有命令。 |
patch | `kubectl patch (-f FILENAME | TYPE NAME |
plugin | kubectl plugin [flags] [options] | 提供用于与插件交互的实用程序。 |
port-forward | kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N] [flags] | 将一个或多个本地端口转发到一个 Pod。 |
proxy | kubectl proxy [--port=PORT] [--www=static-dir] [--www-prefix=prefix] [--api-prefix=prefix] [flags] | 运行访问 Kubernetes API 服务器的代理。 |
replace | kubectl replace -f FILENAME | 基于文件或标准输入替换资源。 |
rollout | kubectl rollout SUBCOMMAND [options] | 管理资源的上线。有效的资源类型包括:Deployment、 DaemonSet 和 StatefulSet。 |
run | `kubectl run NAME --image=image [–env=“key=value”] [–port=port] [–dry-run=server | client |
scale | `kubectl scale (-f FILENAME | TYPE NAME |
set | kubectl set SUBCOMMAND [options] | 配置应用资源。 |
taint | kubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options] | 更新一个或多个节点上的污点。 |
top | kubectl top (PODNODE) [flags] [options] | 查看node、pod 的实时资源使用情况 |
uncordon | kubectl uncordon NODE [options] | 将节点标记为可调度。 |
version | kubectl version [--client] [flags] | 显示运行在客户端和服务器上的 Kubernetes 版本。 |
wait | `kubectl wait ([-f FILENAME] | resource.group/resource.name |
15、高级调度方式
-
节点选择器: nodeSelector、nodeName
-
节点亲和性调度: nodeAffinity
-
Pod亲和性调度:PodAffinity
-
Pod反亲和性调度:podAntiAffinity
15.1 节点选择器nodeSelector、nodeName
cd; mkdir schedule; cd schedule/vi pod-demo.yaml
# 内容为
apiVersion: v1
kind: Pod
metadata:name: pod-demolabels:app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1nodeSelector:disktype: harddiskkubectl apply -f pod-demo.yaml
kubectl get podskubectl describe pod pod-demo
# 运行结果:
Warning FailedScheduling 2m3s (x25 over 3m15s) default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.# 打上标签
kubectl label node node2 disktype=harddisk# 正常启动
kubectl get pods15.2 节点亲和性nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬亲和性,必须满足亲和性。
preferredDuringSchedulingIgnoredDuringExecution 软亲和性,能满足最好,不满足也没关系。
matchExpressions : 匹配表达式,这个标签可以指定一段,例如pod中定义的key为zone,operator为In(包含那些),values为 foo和bar。就是在node节点中包含foo和bar的标签中调度
matchFields : 匹配字段 和上面的意思 不过他可以不定义标签值,可以定义
硬亲和性:
# 选择在 node 有 zone 标签值为 foo 或 bar 值的节点上运行 pod
vi pod-nodeaffinity-demo.yaml
# 内容为
apiVersion: v1
kind: Pod
metadata:name: pod-node-affinity-demolabels:app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: zoneoperator: Invalues:- foo- barkubectl apply -f pod-nodeaffinity-demo.yamlkubectl describe pod pod-node-affinity-demo
# 运行结果:
Warning FailedScheduling 2s (x8 over 20s) default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.# 给其中一个node打上foo的标签
kubectl label node node1 zone=foo# 正常启动
kubectl get pods
软亲和性:
cp pod-nodeaffinity-demo.yaml pod-nodeaffinity-demo-2.yaml vi pod-nodeaffinity-demo-2.yaml
# 内容为
apiVersion: v1
kind: Pod
metadata:name: pod-node-affinity-demo-2labels:app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1affinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- preference:matchExpressions:- key: zoneoperator: Invalues:- foo- barweight: 60kubectl apply -f pod-nodeaffinity-demo-2.yaml
15.3 pod亲和性podAffinity
Pod亲和性场景,我们的k8s集群的节点分布在不同的区域或者不同的机房,当服务A和服务B要求部署在同一个区域或者同一机房的时候,我们就需要亲和性调度了。
labelSelector : 选择跟那组Pod亲和
namespaces : 选择哪个命名空间
topologyKey : 指定节点上的哪个键; 对应的值是 node 上的一个标签名称,比如各别节点 zone=A 标签,各别节点有 zone=B 标签,pod affinity topologyKey 定义为 zone,那么调度 pod 的时候就会围绕着 A 拓扑,B 拓扑来调度,而相同拓扑下的 node
就为"同一位置"。如果基于各个节点kubernetes.io/hostname标签作为评判标准,那么很明显“同一位置”意味着同一节点,不同节点既为不同位置,
kubectl get pods
kubectl delete pod pod-node-affinity-demo pod-node-affinity-demo-2 pod-democd ~/schedule/vi pod-required-affinity-demo.yaml
# 内容为:
apiVersion: v1
kind: Pod
metadata:name: pod-firstlabels:app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:name: pod-secondlabels:app: dbtier: db
spec:containers:- name: busyboximage: busyboximagePullPolicy: IfNotPresentcommand: ["sh","-c","sleep 3600"]affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- {key: app, operator: In, values: ["myapp"]}topologyKey: kubernetes.io/hostnamekubectl apply -f pod-required-affinity-demo.yaml kubectl get pods -o wide
# 运行结果,两个 pod 在同一 node 节点上
NAME READY STATUS RESTARTS AGE IP NODE
pod-first 1/1 Running 0 11s 10.244.1.6 node1
pod-second 1/1 Running 0 11s 10.244.1.5 node1
15.4 podAntiAffinity
Pod反亲和性场景,当应用服务A和数据库服务B要求尽量不要在同一台节点上的时候。
kubectl delete -f pod-required-affinity-demo.yaml cp pod-required-affinity-demo.yaml pod-required-anti-affinity-demo.yaml vi pod-required-anti-affinity-demo.yaml
# 内容为
apiVersion: v1
kind: Pod
metadata:name: pod-firstlabels:app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:name: pod-secondlabels:app: backendtier: db
spec:containers:- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentcommand: ["sh","-c","sleep 3600"]affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- {key: app, operator: In, values: ["myapp"]}topologyKey: kubernetes.io/hostnamekubectl apply -f pod-required-anti-affinity-demo.yaml kubectl get pods -o wide
# 运行结果,两个 pod 不在同一个 node
NAME READY STATUS RESTARTS AGE IP NODE
pod-first 1/1 Running 0 5s 10.244.2.4 node2
pod-second 1/1 Running 0 5s 10.244.1.7 node1kubectl delete -f pod-required-anti-affinity-demo.yaml # 如果硬反亲和性定义的标签两个节点都有,则第二个 Pod 没法进行调度,如下面的的 zone=foo
# 给两个 node 打上同一个标签 zone=foo
kubectl label nodes node2 zone=foo
kubectl label nodes node1 zone=foovi pod-required-anti-affinity-demo.yaml
# 内容为:
apiVersion: v1
kind: Pod
metadata:name: pod-firstlabels:app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:name: pod-secondlabels:app: backendtier: db
spec:containers:- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentcommand: ["sh","-c","sleep 3600"]affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- {key: app, operator: In, values: ["myapp"]}topologyKey: zonekubectl apply -f pod-required-anti-affinity-demo.yaml kubectl get pods -o wide
# 结果如下,pod-second 没法启动
NAME READY STATUS RESTARTS AGE IP NODE
pod-first 1/1 Running 0 12s 10.244.1.8 node1
pod-second 0/1 Pending 0 12s <none> <none>kubectl delete -f pod-required-anti-affinity-demo.yaml
15.5 污点容忍调度(Taint和Toleration)
taints and tolerations 允许将某个节点做标记,以使得所有的pod都不会被调度到该节点上。但是如果某个pod明确制定了 tolerates 则可以正常调度到被标记的节点上。
# 可以使用命令行为 Node 节点添加 Taints:
kubectl taint nodes node1 key=value:NoSchedule
operator可以定义为:
Equal:表示key是否等于value,默认
Exists:表示key是否存在,此时无需定义value
tain 的 effect 定义对 Pod 排斥效果:
NoSchedule:仅影响调度过程,对现存的Pod对象不产生影响;
NoExecute:既影响调度过程,也影响显著的Pod对象;不容忍的Pod对象将被驱逐
PreferNoSchedule: 表示尽量不调度
# 查看节点的 taint
kubectl describe node master
kubectl get pods -n kube-system
kubectl describe pods kube-apiserver-master -n kube-system# 为 node1 打上污点
kubectl taint node node1 node-type=production:NoSchedulevi deploy-demo.yaml
# 内容为:
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploynamespace: default
spec:replicas: 2selector:matchLabels:app: myapprelease: canarytemplate:metadata:labels:app: myapprelease: canaryspec:containers:- name: myappimage: ikubernetes/myapp:v1ports:- name: httpcontainerPort: 80kubectl apply -f deploy-demo.yaml kubectl get pods -o wide
# 运行结果:
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-69b47bc96d-cwt79 1/1 Running 0 5s 10.244.2.6 node2
myapp-deploy-69b47bc96d-qqrwq 1/1 Running 0 5s 10.244.2.5 node2# 为 node2 打上污点
kubectl taint node node2 node-type=dev:NoExecute# NoExecute 将会驱逐没有容忍该污点的 pod,因两个node节点都有污点,pod没有定义容忍,导致没有节点可以启动pod
kubectl get pods -o wide
# 运行结果:
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-69b47bc96d-psl8f 0/1 Pending 0 14s <none> <none>
myapp-deploy-69b47bc96d-q296k 0/1 Pending 0 14s <none> <none># 定义Toleration(容忍)
vi deploy-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploynamespace: default
spec:replicas: 2selector:matchLabels:app: myapprelease: canarytemplate:metadata:labels:app: myapprelease: canaryspec:containers:- name: myappimage: ikubernetes/myapp:v2ports:- name: httpcontainerPort: 80tolerations:- key: "node-type"operator: "Equal"value: "production"effect: "NoSchedule"kubectl apply -f deploy-demo.yaml# pod 容忍 node1 的 tain ,可以在 node1 上运行
ubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-65cc47f858-tmpnz 1/1 Running 0 10s 10.244.1.10 node1
myapp-deploy-65cc47f858-xnklh 1/1 Running 0 13s 10.244.1.9 node1# 定义Toleration,是否存在 node-type 这个key 且 effect 值为 NoSchedule
vi deploy-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploynamespace: default
spec:replicas: 2selector:matchLabels:app: myapprelease: canarytemplate:metadata:labels:app: myapprelease: canaryspec:containers:- name: myappimage: ikubernetes/myapp:v2ports:- name: httpcontainerPort: 80tolerations:- key: "node-type"operator: "Exists"value: ""effect: "NoSchedule"kubectl apply -f deploy-demo.yamlkubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-559f559bcc-6jfqq 1/1 Running 0 10s 10.244.1.11 node1
myapp-deploy-559f559bcc-rlwp2 1/1 Running 0 9s 10.244.1.12 node1##定义Toleration,是否存在 node-type 这个key 且 effect 值为空,则包含所有的值
vi deploy-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploynamespace: default
spec:replicas: 2selector:matchLabels:app: myapprelease: canarytemplate:metadata:labels:app: myapprelease: canaryspec:containers:- name: myappimage: ikubernetes/myapp:v2ports:- name: httpcontainerPort: 80tolerations:- key: "node-type"operator: "Exists"value: ""effect: ""kubectl apply -f deploy-demo.yaml# 两个 pod 均衡调度到两个节点
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-5d9c6985f5-hn4k2 1/1 Running 0 2m 10.244.1.13 node1
myapp-deploy-5d9c6985f5-lkf9q 1/1 Running 0 2m 10.244.2.7 node2Port: 80tolerations:- key: "node-type"operator: "Exists"value: ""effect: "NoSchedule"kubectl apply -f deploy-demo.yamlkubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-559f559bcc-6jfqq 1/1 Running 0 10s 10.244.1.11 node1
myapp-deploy-559f559bcc-rlwp2 1/1 Running 0 9s 10.244.1.12 node1##定义Toleration,是否存在 node-type 这个key 且 effect 值为空,则包含所有的值
vi deploy-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploynamespace: default
spec:replicas: 2selector:matchLabels:app: myapprelease: canarytemplate:metadata:labels:app: myapprelease: canaryspec:containers:- name: myappimage: ikubernetes/myapp:v2ports:- name: httpcontainerPort: 80tolerations:- key: "node-type"operator: "Exists"value: ""effect: ""kubectl apply -f deploy-demo.yaml# 两个 pod 均衡调度到两个节点
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-5d9c6985f5-hn4k2 1/1 Running 0 2m 10.244.1.13 node1
myapp-deploy-5d9c6985f5-lkf9q 1/1 Running 0 2m 10.244.2.7 node2