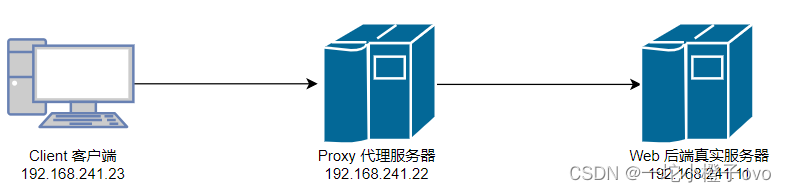
想要在PDF文件中,解析获取全部的标题,是一件比较麻烦的事情。正是因为PDF文件中的内容可能是五花八门的格式(论文、财报、法律条文、图书、报纸、等等)。
但是获取标题信息,又是一件非常重要的事情。标题中往往蕴含着非常多的概括性信息。本文将介绍一种较为准确的提取标题的方式。使用python组件+LLM。本文会给出调试后的可运行代码,以及prompt,还有运行结果。
本文测试以一篇微软的论文为例。论文地址:https://arxiv.org/pdf/2303.07678.pdf
一、技术选型
python组件使用 PyMuPDF,模型使用通义千问。
二、安装使用 pdf解析工具 PyMuPDF
2.1 PyMuPDF安装方式
pip install PyMuPDF2.2 调试后的代码
import fitzdef extract_titles_from_pdf(pdf_path, thres=1.1):doc = fitz.open(pdf_path)titles = []for page_num in range(len(doc)):page = doc.load_page(page_num)blocks = page.get_text("dict")["blocks"]# 获取当前页的页码page_number = page_num + 1# 寻找每一页可能的标题page_titles = []for block in blocks:# 获取文本块的字体大小sizes = [span["size"] for line in block["lines"] for span in line["spans"]]avg_size = sum(sizes) / max(len(sizes), 1)# 判断是否可能是标题if avg_size > thres:text = " ".join([span["text"] for line in block["lines"] for span in line["spans"]])# 排除正文、表格、图片和公式,只保留可能的标题if not is_body_text(text) and not is_table(text) and not is_image(text) and not is_formula(text):# 将标题、页码添加到结果中page_titles.append((text.strip(), page_number))# 将该页的标题添加到结果列表中titles += page_titlesreturn titlesdef is_body_text(text):# 根据文本的长度和内容等特征,判断是否为正文# 这里可以根据具体的PDF文件的特点来定义规则# 以下只是一个示例,可能需要根据实际情况进行调整return len(text) > 100 or text.endswith(".") or text.endswith("?") or text.endswith("!")def is_table(text):# 根据文本的结构和内容特征,判断是否为表格# 这里可以根据表格的特点来定义规则# 以下只是一个示例,可能需要根据实际情况进行调整return " " in text or "\t" in text or " | " in textdef is_image(text):# 根据文本的特征,判断是否为图像# 这里可以根据图像的特点来定义规则# 以下只是一个示例,可能需要根据实际情况进行调整return text.startswith("Image:") or text.startswith("Figure:")def is_formula(text):# 根据文本的特征,判断是否为公式# 这里可以根据公式的特点来定义规则# 以下只是一个示例,可能需要根据实际情况进行调整return text.startswith("Formula:") or text.startswith("Equation:")# 指定要解析的 PDF 文件路径
pdf_path = "D:\\angus\\工作文档\\paper\\Rewrite\\微软query扩写 Query2doc Query Expansion with Large Language Models-2303.07678.pdf"# 调用函数提取标题内容
titles_with_page_numbers = extract_titles_from_pdf(pdf_path)# 打印提取到的标题内容和对应的页码
for i, (title, page_number) in enumerate(titles_with_page_numbers):print(f"Title {i + 1}: {title} (Page {page_number})")2.3 输出的效果
此时,输出比较乱,还不能找到标题,但是标题已经藏在了下边的内容中。接下来就是如何挖掘到真正的标题。
Title 1: Query2doc: Query Expansion with Large Language Models (Page 1)
Title 2: Abstract (Page 1)
Title 3: 1 Introduction (Page 1)
Title 4: 2 Method (Page 2)
Title 5: Write a passage that answers the given query: (Page 2)
Title 6: LLM Prompts (Page 2)
Title 7: LLM Output (Page 2)
Title 8: Method Fine-tuning MS MARCO dev TREC DL 19 TREC DL 20 (Page 3)
Title 9: MRR@10 R@50 R@1k nDCG@10 nDCG@10 (Page 3)
Title 10: Sparse retrieval BM25 ✗ 18.4 58.5 85.7 51.2 ∗ 47.7 ∗ (Page 3)
Title 11: + query2doc ✗ 21.4 +3.0 65.3 +6.8 91.8 +6.1 66.2 +15.0 62.9 +15.2 (Page 3)
Title 12: BM25 + RM3 ✗ 15.8 56.7 86.4 52.2 47.4 docT5query ( Nogueira and Lin ) ✓ 27.7 75.6 94.7 64.2 - (Page 3)
Title 13: 3 Experiments (Page 3)
Title 14: 3.1 Setup (Page 3)
Title 15: 3.2 Main Results (Page 3)
Title 16: 4 Analysis (Page 3)
Title 17: DBpedia NFCorpus Scifact Trec-Covid Touche2020 (Page 4)
Title 18: BM25 31.3 32.5 66.5 65.6 36.7 + query2doc 37.0 +5.7 34.9 +2.4 68.6 +2.1 72.2 +6.6 39.8 +3.1 (Page 4)
Title 19: # params TREC 19 TREC 20 (Page 4)
Title 20: 1 10 30 50 100 (Page 4)
Title 21: % labeled data for fine-tuning (Page 4)
Title 22: 20 (Page 4)
Title 23: 22 (Page 4)
Title 24: 24 (Page 4)
Title 25: 26 (Page 4)
Title 26: 28 (Page 4)
Title 27: 30 (Page 4)
Title 28: 32 (Page 4)
Title 29: 34 (Page 4)
Title 30: 36 (Page 4)
Title 31: MRR on dev set (Page 4)
Title 32: 21.4 (Page 4)
Title 33: 27.3 (Page 4)
Title 34: 31.4 (Page 4)
Title 35: 32.8 (Page 4)
Title 36: 33.7 (Page 4)
Title 37: 22.7 (Page 4)
Title 38: 28.5 (Page 4)
Title 39: 32.1 (Page 4)
Title 40: 34.1 (Page 4)
Title 41: 35.1 (Page 4)
Title 42: DPR w/o query2doc DPR w/ query2doc (Page 4)
Title 43: TREC 19 TREC 20 (Page 4)
Title 44: BM25 + query2doc 66.2 62.9 w/ query only 51.2 47.7 w/ pseudo-doc only 48.7 44.5 (Page 4)
Title 45: 1 Refer to https://en.wikipedia.org/wiki/It’s_a_ Jungle_Out_There_(song) (Page 4)
Title 46: query who killed nicholas ii of russia (Page 5)
Title 47: query who sings monk theme song (Page 5)
Title 48: 5 Related Work (Page 5)
Title 49: 6 Conclusion (Page 5)
Title 50: Limitations (Page 6)
Title 51: LLM call Index search (Page 6)
Title 52: BM25 - 16ms + query2doc >2000ms 177ms (Page 6)
Title 53: References (Page 6)
Title 54: Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and (Page 6)
Title 55: A Implementation Details (Page 8)
Title 56: DPR w/ distillation (Page 8)
Title 57: For dense retrieval experiments in Table (Page 8)
Title 58: B Exploring Other Prompting Strategies (Page 8)
Title 59: DL 2019 DL 2020 (Page 8)
Title 60: Query2doc 69.2 64.5 + iterative prompt 68.6 64.8 (Page 8)
Title 61: Query: {{query}} (Page 8)
Title 62: # Begin of passage {{passage}} # End of passage (Page 8)
Title 63: query who sings hey good looking (Page 9)
Title 64: query trumbull marriott fax number (Page 9)
Title 65: query what is hra and hsa (Page 9)
Title 66: DL 2019 DL 2020 (Page 9)
Title 67: Average 64.8 60.9 Std dev. ± 1.14 ± 1.63 (Page 9)
Title 68: C Results Across Multiple Runs (Page 9)
Title 69: prompts (Page 10)
Title 70: Write a passage that answers the given query: (Page 10)三、使用LLM提取标题
期初,我还想通过规则来挖掘到真正的标题。实际上由于文件五花八门,我们很难通过一个标准的规则去适应各种各样的文件。花了一上午的时间,连一篇论文的标题都没能准确的提取出来。更何况去适配千奇百怪的文件呢?最后效果不一定好,而且会把自己累死。
于是想到了LLM,尝试用LLM来提炼上个步骤中的输出。
这里使用的是阿里的通义千问。
3.1 prompt
以下是一个文件的内容,请帮我分析提取真正的标题。
要求:只需要根据内容,判断是否可以是标题。不要额外生成任何内容!!
内容如下 :
{Title 1: Query2doc: Query Expansion with Large Language Models (Page 1)
Title 2: Abstract (Page 1)
Title 3: 1 Introduction (Page 1)
Title 4: 2 Method (Page 2)
Title 5: Write a passage that answers the given query: (Page 2)
Title 6: LLM Prompts (Page 2)
Title 7: LLM Output (Page 2)
Title 8: Method Fine-tuning MS MARCO dev TREC DL 19 TREC DL 20 (Page 3)
Title 9: MRR@10 R@50 R@1k nDCG@10 nDCG@10 (Page 3)
Title 10: Sparse retrieval BM25 ✗ 18.4 58.5 85.7 51.2 ∗ 47.7 ∗ (Page 3)
Title 11: + query2doc ✗ 21.4 +3.0 65.3 +6.8 91.8 +6.1 66.2 +15.0 62.9 +15.2 (Page 3)
Title 12: BM25 + RM3 ✗ 15.8 56.7 86.4 52.2 47.4 docT5query ( Nogueira and Lin ) ✓ 27.7 75.6 94.7 64.2 - (Page 3)
Title 13: 3 Experiments (Page 3)
Title 14: 3.1 Setup (Page 3)
Title 15: 3.2 Main Results (Page 3)
Title 16: 4 Analysis (Page 3)
Title 17: DBpedia NFCorpus Scifact Trec-Covid Touche2020 (Page 4)
Title 18: BM25 31.3 32.5 66.5 65.6 36.7 + query2doc 37.0 +5.7 34.9 +2.4 68.6 +2.1 72.2 +6.6 39.8 +3.1 (Page 4)
Title 19: # params TREC 19 TREC 20 (Page 4)
Title 20: 1 10 30 50 100 (Page 4)
Title 21: % labeled data for fine-tuning (Page 4)
Title 22: 20 (Page 4)
Title 23: 22 (Page 4)
Title 24: 24 (Page 4)
Title 25: 26 (Page 4)
Title 26: 28 (Page 4)
Title 27: 30 (Page 4)
Title 28: 32 (Page 4)
Title 29: 34 (Page 4)
Title 30: 36 (Page 4)
Title 31: MRR on dev set (Page 4)
Title 32: 21.4 (Page 4)
Title 33: 27.3 (Page 4)
Title 34: 31.4 (Page 4)
Title 35: 32.8 (Page 4)
Title 36: 33.7 (Page 4)
Title 37: 22.7 (Page 4)
Title 38: 28.5 (Page 4)
Title 39: 32.1 (Page 4)
Title 40: 34.1 (Page 4)
Title 41: 35.1 (Page 4)
Title 42: DPR w/o query2doc DPR w/ query2doc (Page 4)
Title 43: TREC 19 TREC 20 (Page 4)
Title 44: BM25 + query2doc 66.2 62.9 w/ query only 51.2 47.7 w/ pseudo-doc only 48.7 44.5 (Page 4)
Title 45: 1 Refer to https://en.wikipedia.org/wiki/It’s_a_ Jungle_Out_There_(song) (Page 4)
Title 46: query who killed nicholas ii of russia (Page 5)
Title 47: query who sings monk theme song (Page 5)
Title 48: 5 Related Work (Page 5)
Title 49: 6 Conclusion (Page 5)
Title 50: Limitations (Page 6)
Title 51: LLM call Index search (Page 6)
Title 52: BM25 - 16ms + query2doc >2000ms 177ms (Page 6)
Title 53: References (Page 6)
Title 54: Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and (Page 6)
Title 55: A Implementation Details (Page 8)
Title 56: DPR w/ distillation (Page 8)
Title 57: For dense retrieval experiments in Table (Page 8)
Title 58: B Exploring Other Prompting Strategies (Page 8)
Title 59: DL 2019 DL 2020 (Page 8)
Title 60: Query2doc 69.2 64.5 + iterative prompt 68.6 64.8 (Page 8)
Title 61: Query: {{query}} (Page 8)
Title 62: # Begin of passage {{passage}} # End of passage (Page 8)
Title 63: query who sings hey good looking (Page 9)
Title 64: query trumbull marriott fax number (Page 9)
Title 65: query what is hra and hsa (Page 9)
Title 66: DL 2019 DL 2020 (Page 9)
Title 67: Average 64.8 60.9 Std dev. ± 1.14 ± 1.63 (Page 9)
Title 68: C Results Across Multiple Runs (Page 9)
Title 69: prompts (Page 10)
Title 70: Write a passage that answers the given query: (Page 10)}3.2 LLM最后的输出
基于内容分析,真正的标题可能包括但不限于以下几项:Title 1: Query2doc: Query Expansion with Large Language Models (Page 1)
Title 2: Abstract (Page 1)
Title 3: 1 Introduction (Page 1)
Title 4: 2 Method (Page 2)
Title 13: 3 Experiments (Page 3)
Title 16: 4 Analysis (Page 3)
Title 48: 5 Related Work (Page 5)
Title 49: 6 Conclusion (Page 5)
Title 50: Limitations (Page 6)
Title 53: References (Page 6)
Title 55: A Implementation Details (Page 8)
Title 56: DPR w/ distillation (Page 8)
Title 58: B Exploring Other Prompting Strategies (Page 8)
Title 68: C Results Across Multiple Runs (Page 9)
以上这些标题通常在学术论文或其他类型的技术文档中作为各个主要部分的标题使用,它们标识了文档结构的不同章节和内容主题。其他带有编号的行更多的是文档内的副标题、子章节、表格标题或具体的数据说明,而非一级或二级标题。四、结论
在经过LLM以后,最终标题提取的准确率已经非常高了!除了提取出来标题,我们还获取到了页码。此时还可以去PDF页面导航了。
不管是什么样格式的文件,我们都可以先解析,大致获取标题,可能不准确。然后再过一次模型,即可获取到准确的标题。
五、思考
当涉及到版面分析时,可以使用文本块的布局信息来判断标题。具体来说,可以根据文本块的相对位置和字体大小等信息来识别可能的标题。以下是一种可能的思路:
-
检测文本块的位置:首先,遍历每一页的文本块,并获取它们的位置信息。可以考虑使用文本块的坐标信息,例如左上角和右下角的坐标。
-
检测文本块的字体大小:对于每个文本块,可以获取其包含文本的字体大小。这将有助于识别较大的文本块,通常标题的字体大小较大。
-
根据位置和字体大小判断标题:结合文本块的位置和字体大小信息,可以应用一些启发式规则来判断哪些文本块可能是标题。例如,可以考虑位于页面顶部且字体较大的文本块,或者是与上一文本块的垂直距离较远的文本块。
-
合并相邻文本块:有时候,标题可能被分割成多个文本块。在识别可能的标题后,可以尝试将相邻的文本块合并成一个标题。
-
去除重复和错误的标题:在提取了所有可能的标题后,可以进行一些后处理步骤,例如去除重复的标题或者根据一些特定规则去除错误的标题。
综上所述,通过结合文本块的位置和字体大小信息,可以设计一种版面分析的方法来提取 PDF 文件中的标题。这种方法可能会更加准确和可靠,因为它更多地利用了文本的布局信息。