📕参考:西瓜书+ysu老师课件+博客(3)聚类算法之DBSCAN算法 - 知乎 (zhihu.com)
目录
1.聚类任务
2.聚类算法的实现
2.1 划分式聚类方法
2.1.1 k均值算法
k均值算法基本原理:
k均值算法算法流程:
2.2 基于密度聚类方法
2.2.1 DBSCAN
DBSCAN的基本概念
DBSCAN算法定义
2.3 基于层次聚类方法
2.3.1 AGNES
AGNES算法流程
【涉及到的英文单词】
无监督学习 unsupervised learning
聚类 clustering
簇 cluster
簇标记 cluster label
有效性指标 validity index
簇内相似度 intra-cluster similarity
簇间相似度 inter-cluster similarity
外部指标 external index
内部指标 internal index
基于原型的聚类 prototype-based clustering
基于密度的聚类 density-based clustering
噪声 noise
异常 anomaly
DBSCAN Density-Based Spatial Clustering of Applications with Noise
AGNES Agglomerative Nesting
1.聚类任务
【聚类任务的引入】
- 在“无监督学习” (unsupervised learning) 中,训练样本的标记信息是未知的。
- 目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
- 此类任务中研究最多、应用最广的是“聚类”。
【什么是聚类】
聚类,试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。
通过这样的划分,每个簇可能对应一些潜在的概念(类别),如“浅色瓜”、“深色瓜”、“有籽瓜”、“无籽瓜”......
【注】这些概念对聚类算法而言,是未知的。聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
接下来谈一下聚类算法的聚类指标——性能度量
聚类性能度量,亦称为聚类“有效性指标”(validity index)。
与监督学习中的性能度量作用类似,对聚类结果,我们需要通过某种性能度量来评估其好坏;另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标。
聚类是将样本集D划分为若干互不相交的子集,即样本簇。那么什么样的聚类结果比较好呢?
直观上,我们希望“物以类聚”,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。
也就是,聚类结果的“簇内相似度”(intra-cluster similarity)高,且“簇间相似度”(inter-cluster similarity)低,这样的聚类效果较好。
【聚类性能度量】:
外部指标(external index):将聚类结果与某个“参考模型” 进行比较
内部指标(internal index):直接考察聚类结果而不使用任何参考模型
【外部指标】:


【内部指标】


补充,距离计算

2.聚类算法的实现
【原型聚类】
“原型”是指样本空间中具有代表性的点。
原型聚类,此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。
2.1 划分式聚类方法
基于划分的聚类方法 :
给定一个数据集 D,其包含有 n 个数据对象,用一个划分方法来构建数据的 k 个划分,每一个划分表示一个类,且 k≤n。
2.1.1 k均值算法
k均值算法基本原理:
随机选取k个点作为初始的聚类中心点,根据每个样本到聚类中心点之间的距离,把样本归类到相距它距离最近的聚类中心代表的类中,再计算样本均值。
若相邻的两个聚类中心无变化,结束迭代;如若不然,不断重复进行该过程。
k均值算法算法流程:
1.选取质心
随机选择 k 个初始质心,其中 k 是用户指定的参数,即所期望的簇的个数。
2.分配数据点
对于样本中的数据对象,根据它们与聚类中心的距离,按距离最近的准则将它们划分到距离它们最近的聚类中心,形成一个簇。
3.更新聚类中心
根据指派到簇的点,将每个簇的质心更新为该簇所有点的平均值。
4.判断是否结束
判断聚类中心的值是否发生变化,若改变,则重复执行上述步骤;若不变,则输出结果。
2.2 基于密度聚类方法
密度聚类,亦称“基于密度的聚类”(density-based clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。
通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇,以获得最终的聚类结果。
基于密度聚类方法的代表算法是DBSCAN。
2.2.1 DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法):基于一组“邻域”参数 (ϵ,MinPts) 来刻画样本分布的紧密程度。
DBSCAN的基本概念

邻域:就是以
为圆心,
为半径,画一个圆,在圆内的样本点,构成这个邻域
核心对象:如果
密度直达:如果
在
密度可达:就是一系列密度直达的样本点传递,使
看图理解:

画图理解,,,,我的建议是直接看大佬的文
(3)聚类算法之DBSCAN算法 - 知乎 (zhihu.com)
MinPts=5的意思是,如果
DBSCAN算法定义

D中不属于任何簇的样本被认为是噪声 (noise)或异常(anomaly) 样本。
那么,如何从数据集D 中找出满足以上性质的聚类簇呢?
DBSCAN算法先任选数据集中的一个核心对象为“种子”,再由此出发确定相应的聚类簇。
1.找核心对象
根据 (ϵ,MinPts) 对 n 个对象进行搜索,寻找所有的核心对象,构成核心对象集合。
2.成簇
根据上述的核心对象寻找 D 中所有密度相连的样本,构成簇,若上述核心对象已被访问,则剔除出去。
3.重复
重复上述过程,直至核心对象集合为空。
其它问题
- 异常点问题:一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
- 距离度量问题:即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离、曼哈顿距离等。
- 数据点优先级分配问题:例如某些样本可能到两个核心对象的距离都小于 ϵ ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时 DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说DBSCAN的算法不是完全稳定的算法。
这个是大佬的博客里的:(3)聚类算法之DBSCAN算法 - 知乎 (zhihu.com)
2.3 基于层次聚类方法
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。
数据集的划分可以采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。因此可分为聚合层次聚类与划分层次聚类。
- 聚合层次聚类:采用自底向上的策略。开始时 , 每个样本对象自己就是一个类 , 称为原子聚类 , 然后根据这些样本之间的相似性 , 将这些样本对象 ( 原子聚类 ) 进行合并。
- 划分层次聚类:采用自顶向下的策略,它首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件。该种方法一般较少使用。
2.3.1 AGNES
AGNES是一种采用自底向上聚合策略的层次聚类算法。
它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直至达到预设的聚类簇个数。
这里的关键是如何计算聚类簇之间的距离。
实际上,每个簇是一个样本集合,因此只需采用关于集合的某种距离即可。
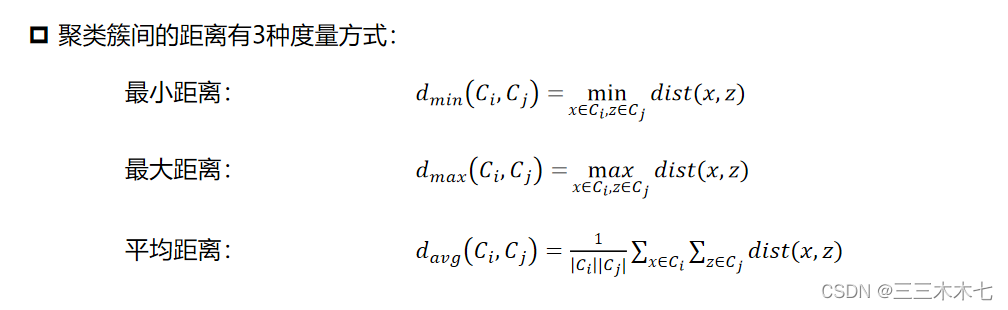
AGNES算法流程
给定包含 n 个对象的数据集 D ,聚类簇距离度量函数 d,聚类簇数为 k。
1.计算所有样本间的距离
使用度量函数 d 计算所有样本间的距离。
2.更新聚类簇及样本间距离
将距离最近的两个聚类簇进行合并,计算合并后的聚类簇间的距离。
3.重复
重复上述过程,直至聚类簇数为设定的参数 k。





![[Flink04] Flink部署实践](https://img-blog.csdnimg.cn/direct/9c94f985a0cd4a7c9b9ea4f89dd047cc.png)